| Author |
Message |
|
robfinch
Joined: Sat Feb 02, 2013 9:40 am
Posts: 2095
Location: Canada

|
I believe the data ready alu performance issue is fixed. The core runs approximately four times as fast now.
Extracted the ip, register file valid, register file source, and some other bits out to their own modules. Trying to make the core more modular. Add to that head and tail pointer logic.
Worked out some of the bugs in the dependency matrix logic.
_________________Robert Finch http://www.finitron.ca
|
| Mon Jun 03, 2019 4:43 am |
 
|
|
|
robfinch
Joined: Sat Feb 02, 2013 9:40 am
Posts: 2095
Location: Canada
|
Been having a lot of fun with sequence numbers. The core uses sequence number to determine the order of instructions in the queue. I finally hit upon the idea of using the tick count to generate a sequence number. The issue is that the sequence number needs to increment all the time. Previously it had been reset when instruction committed, but this didn’t work very well. So, I’ve decided just to use a 33-bit number rather than a 5-bit number, and not have the sequence number reset. It’ll have to be reset programmatically. Found another way to implement branches without using a sequence counter. The idea being to reduce the amount of hardware required. The basic idea is to shade a column of bits black or white according to if the instructions are in the branch shadow. Instead of a sequence number, a mask is generated indicating instructions in the branch shadow. This method requires a bit in the instruction queue for each branch outcome supported. So, I’ve set this to eight outcomes supported for now. That means the core can’t speculate across more than eight branches. When an instruction queues, the mask is set for each active branch. When the branch outcome is finally determined, bits in the mask corresponding to the branch are cleared. The active branches are determined when the instruction queues and a counter is used to select which bit in the mask is associated with the branch. Attachment:
File comment: Branch masking slide
 Branches.png [ 36.21 KiB | Viewed 6353 times ]
Branches.png [ 36.21 KiB | Viewed 6353 times ]
_________________Robert Finch http://www.finitron.ca
|
| Tue Jun 04, 2019 3:49 am |
|
|
|
robfinch
Joined: Sat Feb 02, 2013 9:40 am
Posts: 2095
Location: Canada
|
Added a decode buffer to the core between the cache output and instruction decoding. It should help boost the operating frequency. Having a lot of fun getting the signals pipelined properly.
I finally understood how the g-share branch predictor could be implemented.
The core uses a PowerPC style branch predictor arrangement. The branch address is fed for instruction fetch from the branch target buffer in the first cycle of a branch instruction fetch. During the next cycle an adaptive correlating branch predictor may override the address from the BTB.
Mulling over the idea of using a tagging system for branches. It's tempting to try and implement one and compare resource sizes with the current system.
_________________Robert Finch http://www.finitron.ca
|
| Wed Jun 05, 2019 3:26 am |
|
|
|
Garth
Joined: Tue Dec 11, 2012 8:03 am
Posts: 285
Location: California
|
robfinch wrote: I finally understood how the g-share branch predictor could be implemented.
The core uses a PowerPC style branch predictor arrangement. The branch address is fed for instruction fetch from the branch target buffer in the first cycle of a branch instruction fetch. During the next cycle an adaptive correlating branch predictor may override the address from the BTB. I have not paid much attention to matters of processor design; but I have wondered why not let the programmer tell it if it's likely to branch or not. He always knows the goal of the particular part of the code, and what it's used for, unlike even the smartest compilers. Then the processor could use information from the programmer to prepare the most efficient way to do what he says will usually happen. _________________http://WilsonMinesCo.com/ lots of 6502 resources
|
| Wed Jun 05, 2019 6:03 am |
|
|
|
BigEd
Joined: Wed Jan 09, 2013 6:54 pm
Posts: 1783
|
I thought maybe branching to a new thread would be right:
|
| Wed Jun 05, 2019 8:25 am |
|
|
|
robfinch
Joined: Sat Feb 02, 2013 9:40 am
Posts: 2095
Location: Canada
|
With the transistor budgets available there’s even a move to branch predictors based around neural networks. Branch prediction has gotten really good and complex. As Ed says, it’s back to plain old branches for the programmer. I just had the thought that branches involving the exception link register should always be predicted as not taken, assuming exceptions are the rare case.
It turns out the means for branch stomping (shading columns of bits). I mentioned before seems to work, but I decided to switch to using branch tags, I think it's less hardware.
Changed branches to relative addressing instead of absolute. It’ll make it easier for position independent code. The address is bundle relative however, so the least significant four bits of the address are absolute. It’s unlikely that position independent code would move anything other than bundles around because of the 128-bit bundle format.
I thought using branch tags would be too complex, after several hours of trying to implement something I decided to call it a night. Well the next morning I decided to take another crack at it, and found it to be easy to do, with some limitations. As I’ve implemented it it’s pretty simple. There are enough tags for if there was a branch in every queue slot. A bit ridiculous but it leads to simple logic. That way there’s no worry about keeping track of which tags are used and allocated. The branch tag allocator simply increments for each branch because the tags are always guaranteed to be no longer in use by the time the allocator overflows. So, for an eight-entry queue a three-bit branch tag is used, for a sixteen-entry queue a four-bit tag is used. (It’s log2(# queue entries)).
_________________Robert Finch http://www.finitron.ca
|
| Thu Jun 06, 2019 3:07 am |
|
|
|
robfinch
Joined: Sat Feb 02, 2013 9:40 am
Posts: 2095
Location: Canada
|
Added static branch prediction hardware. It’s just a mux for a couple of bits on the inputs and outputs of the branch predictor.
Worked on the sigmoid approximation function today. Worked also on reciprocal square root estimate function. The implementation uses the method made famous by the Quake game. It takes about 25 clock cycles for the estimate to be calculated. Since it’s performing four floating-point multiplies and a subtract it uses about 2,000 LUTs. It’s being left out of the core for now.
Moved the memissue logic out to its own module.
_________________Robert Finch http://www.finitron.ca
|
| Fri Jun 07, 2019 4:15 am |
|
|
|
BigEd
Joined: Wed Jan 09, 2013 6:54 pm
Posts: 1783
|
Wouldn't the reciprocal square root be a good candidate for a complex microded instruction which re-uses existing hardware?
|
| Fri Jun 07, 2019 7:14 am |
|
|
|
robfinch
Joined: Sat Feb 02, 2013 9:40 am
Posts: 2095
Location: Canada
|
Definitely would be a good candidate for micro-code. I had thought of this but wanted to see how large the code would be without micro-code. It’s just an estimate, so it’s only performing one NR cycle which is accurate to better than 1%. If it was figuring out the value accurate to more bits, I’d go with micro-code. It turns out the FP multipliers aren’t that large, around 100 LUTs because they use DSP slices. The adder is larger. One issue with micro-code is the processor might be able to execute instructions just as fast or faster than micro-code. To gain some performance two of the multiplies are being done in parallel. (Multiplying by 0.5 and squaring y can be done at the same time). Even if micro-coded it would require some parallel hardware. Otherwise may as well just use software.
The estimate is performed in single precision, to use even less hardware I was thinking of lowering the precision and using dedicated multipliers / subtractor. Since only eight or nine mantissa bits are being generated, maybe 24-bit FP (15 man. 8 exp) components could be used.
I tried recoding using a state machine and got the following results:
State machine (micro-coded): 1606 LUTs. (2 multipliers, 1 addsub)
No State machine: 2129 LUTs. (4 multipliers, 1 addsub)
Lookup table (5-6 bits accurate) 133LUTs, (4 block rams)
So, the micro-coded version is smaller by about 25%, the extra operand multiplexors in the micro coded version consume some resources that aren’t required in the non-micro coded version.
I came up with a lookup table version as well. I thought it would require too large of a table, but the table size can be reduced a couple of ways.
Since the lookup uses only six mantissa bits it won’t be accurate to more than six bits. So, there’s no real need to store more than seven or eight bits of the result mantissa. Meaning a 16-bit wide rom would work. Values in the table are 7.9 floating-point format.
By noting the number always has to be positive, the sign bit doesn’t need to be looked up. Also, the square root effectively right-shifts the exponent by one, so in most cases one bit of the exponent doesn’t need to be looked up. That means only seven exponent bits plus six mantissa bits can be used to index an 8k entry table.
A table lookup version uses only 133LUTs and 4 block rams and is accurate to about 3%. Takes only 3 clock cycles.
_________________Robert Finch http://www.finitron.ca
|
| Sat Jun 08, 2019 3:33 am |
|
|
|
robfinch
Joined: Sat Feb 02, 2013 9:40 am
Posts: 2095
Location: Canada
|
Put some elbow grease into the emulator. It isn’t very far along. It’s slow going because I’m learning the ins and outs of C#. Implemented the JMP, CALL, RET, ADD, AND, STB and a couple of other instructions. With just a handful of instructions implemented the emulator is able to run the boot code until sometime after the LEDs are set with the value $AA. The issue in simulation at the moment is the simulation runs for about 150 instructions then dies on a bad return address. I think this is more likely a software problem with the assembler or compiler than an issue with the core. So, I want to see if an emulation can be run to the same point. Found several issues with the assembler output already – branches were always setup to branch to slot zero. EM80 screenshot: Attachment:
File comment: EM80 screenshot
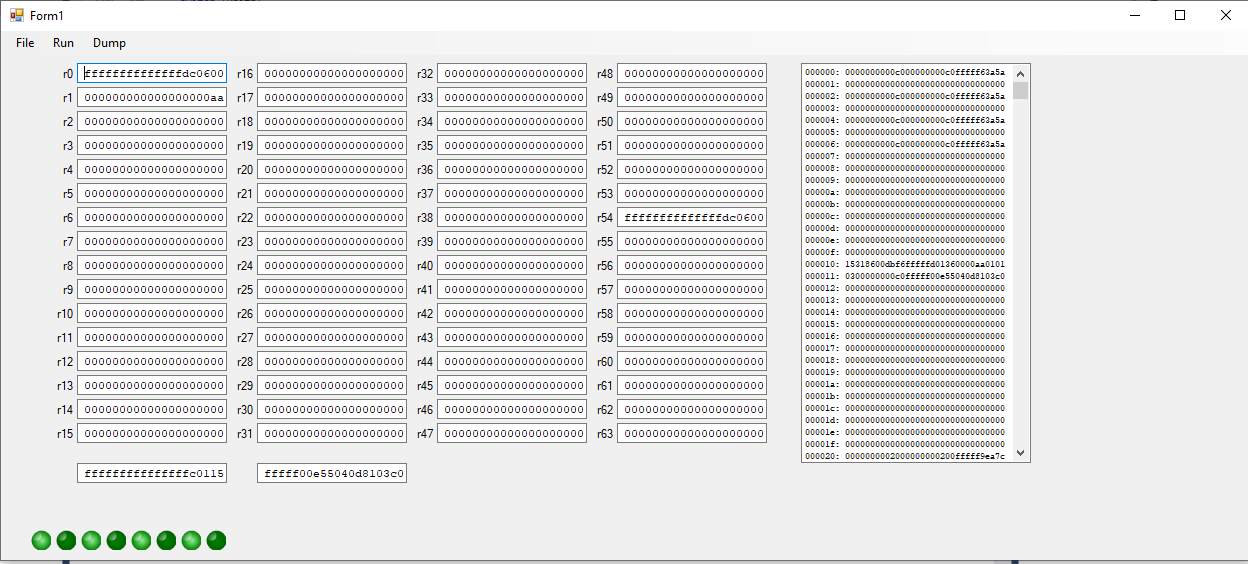 EM80First.png [ 35.3 KiB | Viewed 6238 times ]
EM80First.png [ 35.3 KiB | Viewed 6238 times ]
_________________Robert Finch http://www.finitron.ca
|
| Sun Jun 09, 2019 3:18 am |
|
|
|
robfinch
Joined: Sat Feb 02, 2013 9:40 am
Posts: 2095
Location: Canada
|
Finished off the floating-point adder with a latency of 10 clock cycles. This is a much longer latency than the original adder but should be capable of much higher clock frequencies.
Found out the workstation doesn’t propagate Nan’s the way I thought it was supposed to. It seems to have an extra bit set in the result. I’m leaving my code with Nan propagation as is.
Coded a trunc function today and tried to get IEEE remainder going. The first version of the remainder function I wrote used the FTOI then ITOF functions and came up with correct results about 50% of the time, other results were out-to-lunch. Thinking it had to do with the limitations of the conversions I set about coding the trunc function which truncates off fractional bits without actually doing conversions. Well the trunc function seems to work fine when compared to workstation results. But the results of the remainder operation were even worse. It seems the divide isn’t working properly in the test harness. I haven’t figured out why yet.
IEEE remainder is defined as:
rem = x – round(x/y) * y.
The round is round to integer. There is a simple state machine to use the fp functions (micro-coded).
_________________Robert Finch http://www.finitron.ca
|
| Mon Jun 10, 2019 3:07 am |
|
|
|
robfinch
Joined: Sat Feb 02, 2013 9:40 am
Posts: 2095
Location: Canada
|
The rtfItanium emulator is a little further along now, it can handle a few more of the common instructions and runs for about 100 instructions before crashing. It isn’t quite up to the same point that simulation reaches. The emulator has enough instructions implemented to execute the Sieve of Eratosthenes.
Starting with the FP multiplier, I changed it into a fused multiply-add unit. The benefit of this is less hardware than separate units and less error in the output. The FMA unit is fully pipelined able to process new input every clock cycle with a latency of 17 clocks. There appears to be a pipeline skew issue of some sort, however. Testing the FMA the results appear mangled, unless the test harness waits for the latency to expire. The calculated results also vary from the workstation results sometimes by one in the least significant bit. Sometimes higher, sometimes lower. This could be due to how the test vectors were generated. I’m not sure if an FMA would be used during the generation. I tried changing the rounding mode to round down, and it came up with numbers that were always equal to or one bit less than the ones generated for the test file.
_________________Robert Finch http://www.finitron.ca
|
| Tue Jun 11, 2019 2:47 am |
|
|
|
robfinch
Joined: Sat Feb 02, 2013 9:40 am
Posts: 2095
Location: Canada
|
A couple of fixes to the FMA and addsub. At infinity the (old)addsub wasn’t setting the mantissa to zero. The FMA tracks the underflow exponent from the multiplier now rather than just using an exponent of zero. Found one and fixed one issue with pipelining but results still seem out—of-sync. Better test data was created for the FMA core. The test data had been generated using random doubles, but now it’s generated using random integers whose bit patterns are converted to double. This allows a wider range and invalid double values to be generated.
Managed to work out the pipeline skew problem, there was an always@* in one place where there should have been an always @(posedge clk).
Added four extra datapath bits into the design making the datapath 84 bits internally. The extra bits are for the benefit of floating-point calculations which now maintain the four extra bits in registers. When values are stored the bits are truncated. For general purpose register usage the extra bits could be used to store pointer information. The four extra bits are hidden from the programming model.
I managed to write the queue logic in a parameterized fashion. This will help in the future to vary the number of instructions queued.
_________________Robert Finch http://www.finitron.ca
|
| Wed Jun 12, 2019 3:00 am |
|
|
|
robfinch
Joined: Sat Feb 02, 2013 9:40 am
Posts: 2095
Location: Canada
|
I put the ROM memory in the processing core and it feeds directly into the L1 cache without wasting L2 cache space. Effectively making the L2 cache appear larger. The ROM can now be read in two clock cycles instead of the six or seven required to interface through the L2 cache. I’m wondering why I didn’t do this before. I guess I was just used to the old paradigm of an EPROM on a motherboard. The combined instruction queue / re-order buffer has been split apart into two separate queues which may be different sizes. For some reason the core is much faster now. It gets around to displaying the ‘AA’ status on the LEDs in only 2us. Previously it had taken about 3 to 4 us. Still some bugs in it though, it doesn’t advance the head and tail pointers of the re-order buffer properly yet. Up to 40 instructions are executing correctly, then things go amiss. Attachment:
File comment: rtfItanium Pipeline Diagram
 PipelineDiagram.png [ 16.99 KiB | Viewed 6094 times ]
PipelineDiagram.png [ 16.99 KiB | Viewed 6094 times ]
_________________Robert Finch http://www.finitron.ca
|
| Thu Jun 13, 2019 2:49 am |
|
|
|
BigEd
Joined: Wed Jan 09, 2013 6:54 pm
Posts: 1783
|
Oh, thanks for the picture - worth a thousand words!
|
| Thu Jun 13, 2019 10:11 am |
|
|
Who is online |
Users browsing this forum: No registered users and 14 guests |
|
You cannot post new topics in this forum
You cannot reply to topics in this forum
You cannot edit your posts in this forum
You cannot delete your posts in this forum
You cannot post attachments in this forum
|

|