Quote:
Didn't know about the K6 doing that - I was kinda more in a fixed opcode size mentality, but find it interesting.
sure found it interesting when I first learned of this. Every clock cycle is precious -- every pipeline stage, that is. Apparently the K6 designers looked at the cycle when the cache line fills and said, "This can be more than just a load. We can use predecode logic to simultaneously do some useful work, and store the result." It bloats the cache, because now you have extra bits to store. But those extra bits earn their keep.
On page 11
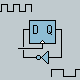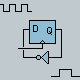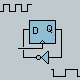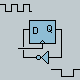
this K6 Data Sheet says, "Decoding x86 instructions is particularly difficult because the instructions are variable-length and can be from 1 to 15 bytes long. Predecode logic supplies the five predecode bits that are associated with each instruction byte. The predecode bits indicate the number of bytes to the start of the next x86 instruction. The predecode bits are stored in an extended instruction cache alongside each x86 instruction byte as shown in Figure 2. The predecode bits are passed with the instruction bytes to the decoders where they assist with parallel x86 instruction decoding."
On a personal note I remember the K6 as a watershed chip because it was my 450 MHz K6-2+ that allowed me to
comfortably view PDF files for the first time. (Wow! Electronic documents!) Up until then I'd been running a clock-quadrupled '486, and for PDFs it just didn't have enough steam!

Jeff