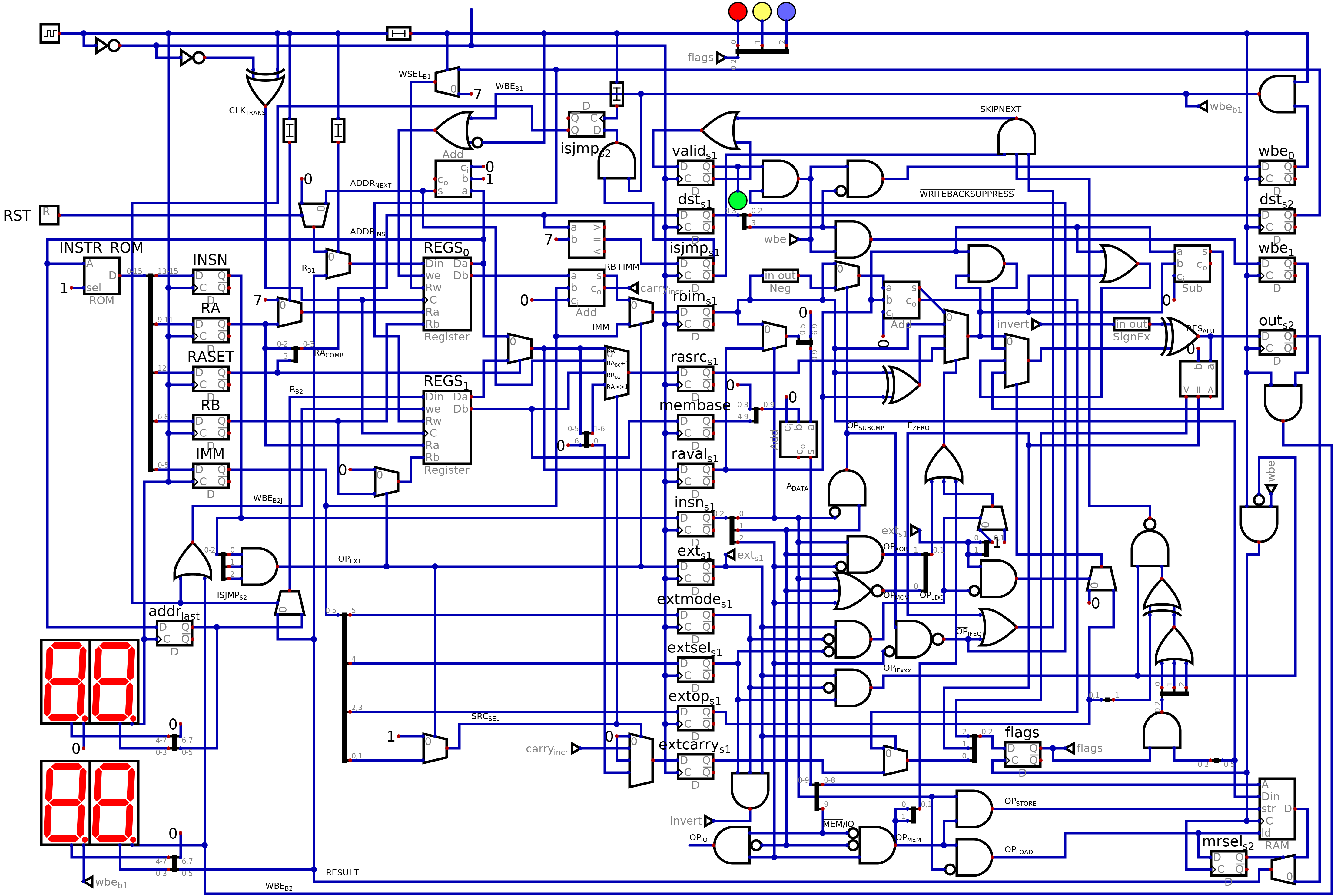
Saw the challenge mentioned on hackaday.io and thought I'd come up with something... and a week or so later here it is:
https://github.com/periata/cpus/tree/master/c61A 6-bit CPU (designed to be implemented in mostly TTL but using a pair of GAL16V8s for the ALU), with a schematic that fits on a single A4 sheet (at readable size), and ISA description that likewise fits a single sheet of paper (<66 lines, 80 cols).
Features:
* Harvard architecture with 16-bit instruction width * 64 words instruction memory (I suspect there's space to expand that by adding a base register to be shifted and added to the PC ... I would probably expand it out to 1Kword if I had any application that needed that right now -- but I'll leave that for the C61A revision and call this one done for now!)
* two stage pipeline: every instruction writes results back immediately after the next instruction reads its operands. no detection of pipeline hazards, so programmer has to determine which registers are safe to use on each instruction!
* 16 registers in two separate banks (R0-R7, R8-R15) in order to allow two registers to change in a single instruction as long as they are in opposite banks.
* R7 is the program counter (so no jump instruction is necessary: just load a new value into R7 to jump)
* R8 is a data memory offset register, which is shifted left by 4 bits and added to address operands in load and store operations, giving a 1Kword data memory (although my implementation only has 512 words and uses the high address bit to select IO operations)
* R15 is a subroutine link register; whenever R7 is explicitly modified, the old value is copied to R15, thus allowing a simple move to be used to perform call and return operations without needing specific instructions, either.
* Two instruction formats:
1. 3 bits opcode (opcode 7 reserved to select alternative format), 4 bits register A, 3 bits register B (only allows R0-R7), 6 bits immediate word (which is always added to the contents of register B to produce the operand)
2. 4 bits register A, 3 bits register B (R8-R15 only), 6 bits opcode
* ALU designed to be implemented using a pair of 3-bit slices in GAL16V8 chips. Operations: add, subtract, xor, negate.
* Additionally to the standard ALU there are and/or/increment/shift right operations available with optional inverted output (these are type 2 instructions, which end up using a different data path rather than the ALU)
* conditional execution of next instruction: if ra == rb+immediate; if last result was none of selection of (zero, negative, carry); if last result was all of selection of (zero, negative, carry)
* The instruction pointer incrementer can be used to provide a post-increment mode on memory writes (although not reads because that would conflict with access to the register file)
* Designed at gate/standard function block level using "Digital" (a replacement for Logisim that I've found to be a little better for certain things). Other than standard logic gates, components used are: register files (equivalent in behaviour to the 74xx871 IC, only 6-bits wide rather than 4, and only using half of the registers in each of the two chips... I'm sure there's a clever way to multiplex them to avoid the redundancy, but I really can't be bothered), 2-in and 4-in multiplexers, D type latches, adders, comparators (comparing to constants only), delay lines, negater
* Schematic mostly shows direct connections between components, however a handful of signals are connected via "tunnel" components, i.e. the connections are labelled rather than drawn. I think there are less than 5 of these, other than this the connection paths shown are the connections needed.
* RAM needs an access time of cycle time minus propagation delay of a single adder and cycle time less than cpu cycle time (e.g. 90ns SRAM for 10MHz operation)
* Instruction memory needs an access time of half a cycle (e.g. 45ns Flash for 10MHz operation)
Haven't tested the design in hardware, but using 74S* chips for the critical path my estimate is that it should be possible to achieve ~10MHz.