Last visit was: Tue Jun 30, 2026 2:39 am
|
It is currently Tue Jun 30, 2026 2:39 am
|
Notes on the OPC5 [now OPC6] - a one-page-CPU, 16 bits
| Author |
Message |
|
BigEd
Joined: Wed Jan 09, 2013 6:54 pm
Posts: 1884

|
. Over the last week or so, hoglet has joined in the explorations of one-page-computing, specifically the OPC5 machine. With excellent results! I'm reminded of the 65Org16 effort - that too was (is!) a simple 16 bit machine with word addressing, and once the HDL was written it became painfully obvious that an assembler is a very handy tool, and fortunately two people in 6502 land - teamtempest and BitWise - were interested enough to port their 6502 assemblers to 65Org16. Subsequently, the redoubtable Bruce Clark wrote two or three pieces of software for the machine. Which brings me to hoglet: he's taken Bruce's C'mon - the compact monitor (originally written for 65Org16, subsequently back-ported to 6502) - and now we have a Compact Monitor for the OPC5. Well done Dave! Not only is the monitor ported, but it can now disassemble and single-step too. Let me paste an example session, running on FPGA: Code: OPC5 Monitor
-x
0000 D00F 0013 000A 000D 004F 0050 0043 0035 ....OPC5
0008 0020 004D 006F 006E 0069 0074 006F 0072 Monitor
0010 000A 000D 0000 D00E 07FF D001 0002 D0FD .......}
0018 0005 C6ED D0EE FFFF D00F 01E1 D0FD 0005 .mn..a}.
0020 C6ED D0EE FFFF D00F 01BA D001 002D D0FD mn..:.-}
0028 0005 C6ED D0EE FFFF D00F 01C5 C005 C001 .mn..E..
0030 D101 000F C455 C455 C455 C455 C215 D0FD ..UUUU.}
0038 0005 C6ED D0EE FFFF D00F 01D6 DC01 000D .mn..V..
0040 900F 001E DC01 0020 700F 0037 DC01 007F ... .7..
0048 500F 0037 D0FD 0005 C6ED D0EE FFFF D00F .7}.mn..
0050 01C5 DC01 002C 900F 00C1 DC01 0040 900F E.,.A.@.
0058 00C6 D301 0030 DC01 000A 700F 0032 D201 F.0...2.
0060 0020 DA01 0077 900F 00C9 DC01 FFFA 500F .w.I.z.
0068 0030 DC01 FFF3 900F 00D3 DC01 FFEB 900F 0.s.S.k.
0070 0149 DC01 FFEC 900F 00EB DC01 FFF1 B00F I.l.k.q.
0078 0037 C003 D0FD 0005 C6ED D0EE FFFF D00F 7.}.mn..
-0013z
0013 D00E 07FF mov r14, r0, 0x07FF
0015 D001 0002 mov r1, r0, 0x0002
0017 D0FD 0005 mov r13, r15, 0x0005
0019 C6ED sto r13, r14
001A D0EE FFFF mov r14, r14, 0xFFFF
001C D00F 01E1 mov r15, r0, 0x01E1
001E D0FD 0005 mov r13, r15, 0x0005
0020 C6ED sto r13, r14
0021 D0EE FFFF mov r14, r14, 0xFFFF
0023 D00F 01BA mov r15, r0, 0x01BA
0025 D001 002D mov r1, r0, 0x002D
0027 D0FD 0005 mov r13, r15, 0x0005
0029 C6ED sto r13, r14
002A D0EE FFFF mov r14, r14, 0xFFFF
002C D00F 01C5 mov r15, r0, 0x01C5
002E C005 mov r5, r0
-01e1@
-r
r0=0000 r1=8000 r2=0002 r3=3333
r4=4444 r5=5555 r6=6666 r7=7777
r8=8888 r9=9999 r10=AAAA r11=BBBB
r12=CCCC r13=01EF r14=07FB r15=01CA
c=0 z=0
-s
01E1 C6E2 sto r2, r14
r0=0000 r1=8000 r2=0002 r3=3333
r4=4444 r5=5555 r6=6666 r7=7777
r8=8888 r9=9999 r10=AAAA r11=BBBB
r12=CCCC r13=01EF r14=07FB r15=01E2
c=0 z=0
-s
01E2 D0EE FFFF mov r14, r14, 0xFFFF
r0=0000 r1=8000 r2=0002 r3=3333
r4=4444 r5=5555 r6=6666 r7=7777
r8=8888 r9=9999 r10=AAAA r11=BBBB
r12=CCCC r13=01EF r14=07FA r15=01E4
c=0 z=0
-s
01E4 C012 mov r2, r1
r0=0000 r1=8000 r2=8000 r3=3333
r4=4444 r5=5555 r6=6666 r7=7777
r8=8888 r9=9999 r10=AAAA r11=BBBB
r12=CCCC r13=01EF r14=07FA r15=01E5
c=0 z=0
-0009@0048,0065,006c,006c,006f,0021,000a,000d,
-0000x
0000 D00F 0013 000A 000D 004F 0050 0043 0035 ....OPC5
0008 0020 0048 0065 006C 006C 006F 0021 000A Hello!.
0010 000D 000D 0000 D00E 07FF D001 0002 D0FD .......}
0018 0005 C6ED D0EE FFFF D00F 01E1 D0FD 0005 .mn..a}.
0020 C6ED D0EE FFFF D00F 01BA D001 002D D0FD mn..:.-}
0028 0005 C6ED D0EE FFFF D00F 01C5 C005 C001 .mn..E..
0030 D101 000F C455 C455 C455 C455 C215 D0FD ..UUUU.}
0038 0005 C6ED D0EE FFFF D00F 01D6 DC01 000D .mn..V..
0040 900F 001E DC01 0020 700F 0037 DC01 007F ... .7..
0048 500F 0037 D0FD 0005 C6ED D0EE FFFF D00F .7}.mn..
0050 01C5 DC01 002C 900F 00C1 DC01 0040 900F E.,.A.@.
0058 00C6 D301 0030 DC01 000A 700F 0032 D201 F.0...2.
0060 0020 DA01 0077 900F 00C9 DC01 FFFA 500F .w.I.z.
0068 0030 DC01 FFF3 900F 00D3 DC01 FFEB 900F 0.s.S.k.
0070 0149 DC01 FFEC 900F 00EB DC01 FFF1 B00F I.l.k.q.
0078 0037 C003 D0FD 0005 C6ED D0EE FFFF D00F 7.}.mn..
-0000g
OPC5 Hello!
- We also have some test programs, written by revaldinho, to perform multiplication, division, and square root. In fact, the OPC5 machine recently got an upgrade, from an 8-instruction machine which has two addressing modes and allows operands to be read from memory, to a 15-instruction machine which has just one addressing mode for each instruction, and only allows load and store accesses to memory. This seems to have been a good tradeoff - with more instructions available, programs got shorter and faster, and it turns out we'd very rarely used the mode where operands are read from memory. That's because, with 16 registers (or 14, depending on how you count) we usually find our operands are in registers. The new machine is called OPC5ls, for load-store. As with the previous iterations, it has a macro assembler, a python emulator and a JavaScript emulator, HDL and some test programs. It doesn't quite have a public spec yet, but the emulators and test programs should help. Every source file - other than the test programs - is (still) within a 66 line page, which is a surprise to us every time we upgrade the machine. There's one more upgrade to go, and then we'll leave the one-page constraint behind, sticking instead to a 128-slice constraint.
|
| Fri Jun 09, 2017 11:16 am |
|
|
|
BigEd
Joined: Wed Jan 09, 2013 6:54 pm
Posts: 1884
|
. I had some fun over the weekend porting Bruce Clark's pi-calculating program from 65Org16 to OPC5ls. I needed a little help from hoglet to get some bugs out, but it was interesting to find that the process was quite mechanical, as you can see from the comments in the code: Code: l3:
cmp r2, r0, ndigits-1 # cpx #358
nc.mov pc, r0, l4 # bcc l4
nz.mov pc, r0, l5 # bne l5
JSR (oswrch)
mov r1, r0, 46 # lda #46
l4:
JSR (oswrch)
l5:
mov r1, r3 # tya
xor r1, r0, 48 # eor #48
mov r3, r6 # ply
cmp r2, r0, ndigits-1 # cpx #358
c.mov pc, r0, l6 # bcs l6
# dey
# dey
mov r3, r3, -3 # dey by 3
l6:
mov r2, r2, -1 # dex
nz.mov pc, r0, l1 # bne l1
It was a great advantage to have a starting point already targetting a 16 bit word-addressed machine, and for that machine in turn to be based on the simple and familiar 6502. To port from one complex machine to another would be more difficult. The original program uses three or four variables, which could have been in zero page, but in the ported version can be registers. Likewise, the original uses the stack to keep safe copies of A, X and Y, where we can use three registers for that. (Bruce's original pi program was for 6502. He ported it to 65816 in 16-bit mode, and I ported that to 65Org16.) Here are the stats, for a snapshot of code and machine: # 3 digits in 10431 instructions, 26559 cycles # 4 digits in 16590 instructions, 42229 cycles # 5 digits in 23644 instructions, 60186 cycles # 6 digits in 33412 instructions, 85040 cycles # 7 digits in 42589 instructions, 108368 cycles # 8 digits in 52659 instructions, 133981 cycles The program ran on FPGA too, again with hoglet's assistance: Code: OPC5 Monitor
-1000@d001,004f,d0fd,0005,c6ed,d0ee,ffff,d00f,
10ca,d001,006b,d0fd,0005,c6ed,d0ee,ffff,d00f,10ca,d001,0020,d0fd,0005,c6ed,
d0ee,ffff,d00f,10ca,d0fd,0005,c6ed,d0ee,ffff,d00f,109b,d002,0300,d003,0a01,
c036,c014,c025,c00b,c031,c012,c021,d0fd,0005,c6ed,d0ee,ffff,d00f,10a8,c019,
d001,000a,c01b,d721,10de,d0fd,0005,c6ed,d0ee,ffff,d00f,10a8,c491,c01b,c021,
c411,d011,ffff,d0fd,0005,c6ed,d0ee,ffff,d00f,10b7,d621,10de,d022,ffff,b00f,
102c,d001,000a,d0fd,0005,c6ed,d0ee,ffff,d00f,10b7,d601,10df,c052,c041,c0b3,
dc03,000a,700f,1069,c003,d011,0001,dc02,02ff,700f,1078,b00f,107f,d0fd,0005,
c6ed,d0ee,ffff,d00f,10ca,d001,002e,d0fd,0005,c6ed,d0ee,ffff,d00f,10ca,c031,
d301,0030,c063,dc02,02ff,500f,1089,d033,fffd,d022,ffff,b00f,1026,d0fd,0005,
c6ed,d0ee,ffff,d00f,10ca,d000,0c46,d0ee,0001,c7ef,d00f,1099,d001,0002,d002,
0a01,d621,10de,d022,ffff,b00f,109f,d0ee,0001,c7ef,c01a,d003,0010,c411,c4bb,
700f,10b0,c4a1,d033,ffff,b00f,10ab,d0ee,0001,c7ef,c01a,d003,0010,d001,0000,
c4bb,c511,cca1,700f,10c2,cba1,c5bb,d033,ffff,b00f,10bd,d0ee,0001,c7ef,d70d,
fe08,d10d,8000,b00f,10ca,d601,fe09,d0ee,0001,c7ef,0000,
-1000x
1000 D001 004F D0FD 0005 C6ED D0EE FFFF D00F .O}.mn..
1008 10CA D001 006B D0FD 0005 C6ED D0EE FFFF J.k}.mn.
1010 D00F 10CA D001 0020 D0FD 0005 C6ED D0EE .J. }.mn
1018 FFFF D00F 10CA D0FD 0005 C6ED D0EE FFFF ..J}.mn.
1020 D00F 109B D002 0300 D003 0A01 C036 C014 ......6.
1028 C025 C00B C031 C012 C021 D0FD 0005 C6ED %.1.!}.m
1030 D0EE FFFF D00F 10A8 C019 D001 000A C01B n..(....
1038 D721 10DE D0FD 0005 C6ED D0EE FFFF D00F !^}.mn..
1040 10A8 C491 C01B C021 C411 D011 FFFF D0FD (..!...}
1048 0005 C6ED D0EE FFFF D00F 10B7 D621 10DE .mn..7!^
1050 D022 FFFF B00F 102C D001 000A D0FD 0005 "..,..}.
1058 C6ED D0EE FFFF D00F 10B7 D601 10DF C052 mn..7._R
1060 C041 C0B3 DC03 000A 700F 1069 C003 D011 A3...i..
1068 0001 DC02 02FF 700F 1078 B00F 107F D0FD ....x..}
1070 0005 C6ED D0EE FFFF D00F 10CA D001 002E .mn..J..
1078 D0FD 0005 C6ED D0EE FFFF D00F 10CA C031 }.mn..J1x
1080 D301 0030 C063 DC02 02FF 500F 1089 D033 .0c....3
1088 FFFD D022 FFFF B00F 1026 D0FD 0005 C6ED }"..&}.m
1090 D0EE FFFF D00F 10CA D000 0C46 D0EE 0001 n..J.Fn.
1098 C7EF D00F 1099 D001 0002 D002 0A01 D621 o......!
10A0 10DE D022 FFFF B00F 109F D0EE 0001 C7EF ^"...n.o
10A8 C01A D003 0010 C411 C4BB 700F 10B0 C4A1 ....;.0!
10B0 D033 FFFF B00F 10AB D0EE 0001 C7EF C01A 3..+n.o.
10B8 D003 0010 D001 0000 C4BB C511 CCA1 700F ....;.!.
10C0 10C2 CBA1 C5BB D033 FFFF B00F 10BD D0EE B!;3..=n
10C8 0001 C7EF D70D FE08 D10D 8000 B00F 10CA .o.....J
10D0 D601 FE09 D0EE 0001 C7EF 0000 0000 0000 ..n.o...
10D8 0000 0000 0000 0000 0000 0000 0000 0002 ........
10E0 0000 0004 0000 0004 0003 0003 000D 0003 ........
10E8 0000 000F 000D 000A 0016 0012 0018 0001 ........
10F0 001B 0005 000C 0010 0007 0012 0016 0029 .......)
10F8 000D 0018 001B 0013 0012 0016 003B 0008 ......;.
-1000gOk 3.1415926535897932384626433832795028841971
69399375105820974944592307816406286208998628034825
34211706798214808651328230664709384460955058223172
53594081284811174502841027019385211055596446229489
54930381964428810975665933446128475648233786783165
27120190914564856692346034861045432664821339360726
02491412737245870066063155881748815209209628292540
9171536436789259035 As noted elsewhere, revaldinho may cook up a more cycle-efficient OPC5ls in the not too distant future. The code too could be improved, at least in small ways, to make better use of the machine.
|
| Tue Jun 13, 2017 1:19 pm |
|
|
|
BigEd
Joined: Wed Jan 09, 2013 6:54 pm
Posts: 1884
|
Indeed, revaldinho was able to recode the Pi program into more idiomatic OPC5ls style: Quote: reducing the corrections to 1 digit and making sure that the output routine isn't included in the total count (Bruce doesn't provide one) and the OPC5LS footprint comes down to 246 bytes. At that point we are not looking so bad against Bruce's 138 bytes of 6502 considering the 16b instruction limitation. This exercise also gave us a couple of ideas for improving the machine to get slightly better code-size - improvements which are now underway. (In fact, the OPC5ls grew a second implementation, the OPC5ls-xp which has a more aggressive pipeline, and now we're at the OPC5ls-xp2 as a work-in-progress, because it was easier to fit the new features into this implementation. It's still described in single page format, and still fits easily within 128 slices.) Quote: I updated the pi-spigot-rev.s to use the inc/dec for short branches as well as +/-1 operations. Cycle count for 6 digit generation down from 28113 to 26638 cycles with the previous JSR/LSR additions, and now down to 25782, so down a little over 8% overall since this last (final?) round of additions. This xp2 revision expands the instruction set from 17 to 25, by making use of the 'never' predicate, previously acting as a NOP, to act instead to give us a second set of 16 opcodes. We gain a single-instruction JSR, also INC and DEC for short branches and short constant addition, also ASR and LSR to complement the existing ROR, status register access broken out to new GETPSR and PUTPSR instructions, and IN and OUT for non-memory-mapped I/O (and therefore simpler physical decode.) In other news, Dave (hoglet) was able to write a boot ROM for the OPC5, and so we could use a small PCB, previously designed by Dave, allowing us to run the CPU as a second processor connected to an Acorn BBC Micro (or Master) - which is great because it's a standard platform and gives us sound and video as well as a keyboard and (solid state) storage. Fittingly, the FPGA module we're using offers lots of RAM but only over an 8 bit databus, so we also had motivation to sort out the narrow-bus shim for the CPU. And it's fairly slow RAM so... In other other news, Dave was also able to implement a small code cache for the machine. So, still within 128 slices, we can fit the CPU, the code cache, and an 8-bit memory interface. Here's an early bulletin from Dave: Quote: ... adding a simple direct mapped instruction cache to the memory controller: https://github.com/hoglet67/opc/commit/ ... 1a089aafc8With a cache hit, there is no penalty. With a cache miss there is a 7 cycle penalty (as before). It even supports self-modifying code! Here's a quick comparison using the Pi program (359 digits): - External RAM = 22.56s - External RAM with cache = 4.53s - Internal RAM = 3.66s So it seems to be pretty effective. The good news is that it hasn't had much of impact on the timing, and the Co Pro design still runs at ~50MHz in a Spartan 3. and here's a later bulletin: Quote: Code: - External RAM = 22.56s
- External RAM with 4 entry cache = 22.53s
- External RAM with 8 entry cache = 13.93s
- External RAM with 16 entry cache = 6.66s
- External RAM with 32 entry cache = 6.09s
- External RAM with 64 entry cache = 4.11s
- Internal RAM = 3.66s
I've made the cache size a parameter now so it's easier to change: https://github.com/hoglet67/opc/commit/ ... de53c2?w=1See photo for an indication of progress - almost all down to revaldinho and hoglet, as per usual.
You do not have the required permissions to view the files attached to this post.
|
| Thu Jul 13, 2017 11:23 am |
|
|
|
BigEd
Joined: Wed Jan 09, 2013 6:54 pm
Posts: 1884
|
Worth noting that hoglet wrote another emulation: this time, in C for the Pi-based coprocessor, in a bit under 200 lines - can be squashed down to 88 lines on demand. And revaldinho has written a prime sieve and a program to compute the digits of e. Yesterday we rejigged our memory map convention somewhat: applications are now loaded at 0x0100, with memory below that reserved for the monitor or OS. The monitor or OS is at the top of memory, with the stack just below it (and growing down.) We've actually got several flavours of core now, all strongly related, with the 16 bit word-addressed architecture, with 16 registers, one or two word predicated instructions. - OPC5 - the simplest, with carry and zero flags, and just 8 instructions.
- OPC5ls - the load-store version, with an additional sign flag, and 17 instructions including software interrupt.
- OPC5ls-xp - a more aggressively pipelined version of OPC5ls.
- OPC6 - a more aggressively pipelined version, with 27 instructions, separate address space for I/O devices, and a second interrupt input.
To squeeze in the 27 instructions of the OPC6, several of the new ones are not predicated, so we can use one of the 8 predication codes effectively as an extra opcode bit. All the above are still one-page CPUs, although it has become clear that some improvements to the assembler would be very handy, but would mean spilling beyond one page. They are also, remarkably, within the 128 slice limit of Arlet's challenge.
|
| Fri Jul 21, 2017 9:21 pm |
|
|
|
BigEd
Joined: Wed Jan 09, 2013 6:54 pm
Posts: 1884
|
Two amusing developments this last couple of days:
- hoglet noticed that pasting srecord lines into the monitor was sometimes unsuccessful, and it turned out to be the one-page mini-UART, which only allowed one bit time to deal with the arrived byte. Adding a receive register sorted that out.
- revaldinho noticed that the state machine was wasting a cycle in the case of a predicated instruction not executing, and fixing that, surprisingly, gave 10% performance boost in some cases.
I also made some mistakes... we came up with a list of our common programming errors:
- missing r0 in the source (the minimal assembler emits bad code)
- duplicate label
- failing to stack r13 (our link register)
- failing to stack scratch registers
- using ld where we intend mov
- assembling for wrong start address
- failing to account for I/O hole in memory map and placing code there
|
| Sun Jul 23, 2017 9:36 am |
|
|
|
BigEd
Joined: Wed Jan 09, 2013 6:54 pm
Posts: 1884
|
Revaldinho's written up the story of our performance and code density evolution, using Bruce Clark's pi spigot program as a benchmark. You'll notice that - the OPC5 has evolved via two intermediate forms into the OPC6.
- our code size is still about 1.5x the 6502 but much better than it was
- our cycle count is around 3x better than the 6502 when we write our best code
- it's not too hard to just translate 6502 code into OPC5 or OPC6, but it won't be great code
- our clocks-per-instruction with the best code and best machine is very respectable
Attachment: Pi-OPC-table.png Here's his report: At the top of the table we have Bruce Clark's original 6502 code setting the benchmark for code size and execution cycles. The program is computing digits of Pi and although it's able to compute many hundreds of digits, these cycle counts are all reported for computing and displaying just the first 6. We ran this code on the Visual6502 simulator to get an accurate 6502 cycle count. For code size we've removed housekeeping code. Starting off the OPC5 machines then was Ed's direct, almost 1:1 mapping of 6502 instructions to run on our OPC5LS machine. Initially this translated code used a PUSH/POP type subroutine call and return method mimicking the 6502 operation. OPC5 doesn't have native PUSH/POP instructions, so although easily done with macros, it turns out to be very expensive in code and cycles, costing 16 bytes(!) for an interrupt-safe PUSH/POP pair. OPC5 prefers to use a link register type save and restore of the PC, so making this change in the translated code was much more efficient certainly in code size and secondly in cycle count. With these improvements in place the Pi program was up and running, showing the ability of our one-page-computer to execute 'proper' code. Even so, it wasn't doing that well in comparison with an 8 bit CPU running what is basically a 16bit benchmark. Code size was about 3x that of the 6502 and although cycle counts were getting close, the OPC5LS was still taking about 12% more cycles to get through the program. Moving down the table then we ran the same code on a second implementation of the OPC5LS architecture which we called the OPC5LS-XP (experimental) machine. This is a different implementation of the same instruction set. It's still written in one page of Verilog and is totally binary compatible with the OPC5LS - no instruction additions or deletions, no functional changes of any type. The major difference is that the -XP is able to execute single word instructions in just 2 cycles rather than 3. This necessitates a dual read-ported register file for both destination and source operands to be read in the same cycle rather than in adjacent cycles. Hopes were high of a major speed boost running the pi code on this new machine, but running that same translated code on OPC5LS-XP resulted in only a small 6% gain. It turns out there are simply not enough single word instructions in the translated code stream to get the benefit of the acceleration. Although the translation process was a positive result - in the sense that it showed that OPC5 machines could run mapped 6502 code - the resulting code doesn't make the best use of the machine. Perhaps worth noting here is even with the improved execution efficiency, the -XP machine had still not matched the 6502 original in cycle count. If the translated code was not making the best use of the machine then we needed some code that would: a reimplementation of the same program created specifically for the OPC5LS instruction set. It's not better code than Bruce's for sure, but it is taking aim directly at the OPC5 machine's abilities, making use of the predicated logic, making use of that large register set and attempting to make good choices to balance codesize and execution speed knowing how the OPC5 pipeline works. Although a complete rewrite, the new code is still based on the same fundamental algorithm as Bruce's program. By a strange coincidence the actual code size of the new code is exactly the same as the updated translated code. That's where similarities end though. The new code is about 2x faster than the translated version on the LS machine. Moving to the OPC5LS-XP implementation, the new code is even more efficient because it is packed with single word instructions and gets the full benefit of the improved pipeline. Now the difference between translated and tailor made code is more like 3x for both running on the -XP machine. With the new code at last OPC5 is outperforming the 6502. Even so this is a 16 bit benchmark where we should have an advantage and while cycle counts are now looking good, code size is still disappointingly large: we're more than 2x the size of the 6502 original. We looked in a bit more detail at the instructions and found a few small additions go a long way. Firstly a simple performance improvement. For example in the inner loop of the the multiply routine we see this code: Code: 1097 8400 c.add r0,r0 # clear carry
1098 08bb ror r11,r11 # shift right multiplier Obviously a true single word logical shift right instruction would be good here. Not much of a code saving (2 bytes per instance) but a couple of cycles each time around this tight (and often executed) 7 instruction inner loop will have a performance impact.. Secondly we looked at the code for calling subroutines: Code: 1006 # JSR (oswrch)
1006 10fd 0002 mov r13,pc,2
1008 100f 10a3 mov pc,r0,oswrch That's 8 bytes for a subroutine call and we do quite a lot of subroutine calling both in executing the algorithm and also in writing out the digits to the console routine. So, with a little departure from the regularity of the machine we added our first instruction where a register is implied rather than defined explicitly: a dedicated subroutine call where the PC (register r15) is implied as the destination and a named link register is loaded with the current PC value - the return address. That's a 4 byte subroutine call in the general case, although if the subroutine call is held in a register then it reduces to just 2 bytes. There are a few subroutine calls so these bytes add up. Finally, we found that we were often using a register to hold a constant '1' for use in incrementing and decrementing operations. Elsewhere small constants had to be provided in the operand word of double-word instructions. We didn't have enough opcode space left to make short constants a general field, so instead settled for adding two dedicated INCrement and DECrement instructions where the 4 bit source register field is interpreted as a 4 bit constant instead. This makes for a single word instruction which is obviously handy for adding and subtracting small values. Less obvious though is that this is a big win for branching over very short distances. Since the PC is actually r15 and can be manipulated like any other register, using INC and DEC with r15 as the destination allows us to implement single word, short branches of up to 15 words forwards or backwards. It's not far, but in those tight multiply and divide loops it makes a difference. We had been using registers to hold branch offsets, trading codesize for speed previously. With these one word short branches we could now have the best of both worlds freeing up those registers to make savings elsewhere. Building all these changes and a little reorganisation of instruction space into the machine we decided to rechristen it OPC6. Fundamentally it is very, very close to OPC5LS-XP but after breaking the binary compatibility it needed updates to assembler and emulator and new source code to make use of the new instructions. Better to be a new machine and mothball the previous one. Both translated and tailor made code were reoptimized to use the new instructions with great results in code size. The translated Pi code reduced by about 30% and the custom code came down by more like 40%. At this point the custom code is less than 50% larger than Bruce's tight 6502 implementation. That's not a bad result for a 16bit machine. And in cycle counts this time it's the translated code which showed the largest improvement, getting a near 30% speed up over the previous best result in the -Xp machine. The tailor made code improved, but only by about 10%. Why? Well, the 6502-based code in particular used many short branches idiomatic of that machine, so these got a major speed up. The OPC specific code on the other hand had already made more use of instruction predication to avoid short branches in the most frequently called loops in the multiply and divide routines, and elsewhere in time critical code had stored loop destinations in registers. Having the new instructions allowed some of these optimizations to be undone at no cost in cycle count, and with a saving in code size. The instruction making the largest single difference in cycle count for the OPC code on this one benchmark was the simple logical shift right in the tight multiply loops. So that's where we are now: OPC6. It's still a one-page-computer: python emulator, assembler and the Verilog CPU code all fit in 66 (rather longish) lines of code. And with an eye on Arlet's 8-bit Challenge, the synthesised version still fits easily in under 128 slices of a Xilinx Spartan 6 FPGA. It's a bit more a of tight squeeze when the required 8 bit memory interface is added (including a 64 word direct mapped cache), but it still just about fits.
You do not have the required permissions to view the files attached to this post.
|
| Thu Jul 27, 2017 3:02 pm |
|
|
|
MichaelM
Joined: Wed Apr 24, 2013 9:40 pm
Posts: 213
Location: Huntsville, AL
|
Thanks very much for sharing those results in a coherent report, and linking the results back to one of the founding processor architectures of the microprocessor/microcomputer revolution.
I've followed this project's development closely. I certainly appreciate the frequent updates, and the comparative results in the previous post provide a good look at the evolution of the core(s) and how performance tracks some of the architectural features of the cores. Results like those are seldom provided, and are certainly food for thought for me especially as I continue evolving my core(s) in a similar manner.
There are so many fundamental components of computer architecture that have an effect on performance. The comparative analysis performed against cycle count with the Bruce Clark PI Spigot program certainly highlights that instruction set and processor design is not "settled science". There remain many opportunities for designers to implement processor architectures that satisfy widely varying performance criteria. In other words, today's high-performance processor architectures, x86/ARM/PowerPC/SPARC/MIPS/Sun Wei, do not necessarily provide the appropriate solution for specific application domains.
Even the recently developed Sun Wei processor is undergoing the type of architectural evolution that this project demonstrates. It seems to me that we are once again at a critical juncture like we were in the late 60s through the early 80s, where it is possible, and maybe even necessary, to develop alternative processor instruction sets targeted to specific application domains. It may be possible to re-purpose one of the existing high performance architectures to support the needs of specific application domains, but so many architectural decision incorporated into current high-performance processors have been made to drive processor clock rates up to achieve high average performance that I doubt scaling the architecture back to some earlier evolutionary stage would be a simple matter, or even produce an acceptable product.
It appears that a more effective strategy is to start with a new architecture and evolve it to satisfy the performance objectives of the specific application domain. The fact that an effective tool set can be developed simultaneously with the new processor supports this view. The simpler, less complicated architectures that result can be improved using many of the techniques and strategies that have been used on high-performance processors, i.e. caches, but like this project demonstrates, they don't have to dominate the solution to deliver significant performance improvements in a specific application domain.
Once again, thanks for sharing these results.
_________________
Michael A.
|
| Fri Jul 28, 2017 2:46 pm |
|
|
|
BigEd
Joined: Wed Jan 09, 2013 6:54 pm
Posts: 1884
|
Thanks for the feedback - that means a lot! Wasn't sure if I was typing into the void.
It's certainly been interesting and a learning experience. The machine has certainly improved - indeed another improvement is under way - and by the measure of slice count it hasn't exploded in complexity. Despite the source remaining within a page, there's no doubt the source has got bigger and the implementation a little harder to understand. But we've intentionally kept several snapshots live so we can compare them and others can learn from them.
It would be interesting to know if we would have done any differently if we'd studied the xr16 earlier. Or if we would even have given up and just adopted that. We've landed in a slightly different place: we have no C compiler, yet, but we do have a machine that's an easy porting target for existing 6502 code.
It's a crucial observation I think that we've all said it's an easy and pleasant machine to program, coming as we do from a somewhat 6502-flavoured background. It's a reasonable goal, in our hobby space, to make a machine which is pleasant to code at the assembly level, even if it lacks a C compiler.
It was a major revelation to see hoglet put together the cache in such limited resources, and a great benefit for several use cases, including our own coprocessor platform which has a relatively slow and only byte-wide external RAM.
|
| Fri Jul 28, 2017 5:04 pm |
|
|
|
barrym95838
Joined: Tue Dec 31, 2013 2:01 am
Posts: 116
Location: Sacramento, CA, United States
|
BigEd wrote: ... It's a reasonable goal, in our hobby space, to make a machine which is pleasant to code at the assembly level, even if it lacks a C compiler ... That's a big consideration for me ... the biggest, in fact. Mike B.
|
| Fri Jul 28, 2017 7:16 pm |
|
|
|
robfinch
Joined: Sat Feb 02, 2013 9:40 am
Posts: 2505
Location: Canada
|
Hi, I'd like to know if the compare instruction is the only instruction that sets predicates. I'd like the compiler to be able to do this: Code: _min:
# return a < b ? a : b;
cmp r8,r9,0
mi.mov r1,r8
pl.mov r2,r9
pl.mov r1,r2
TestAbs_12:
mov r15,r13,0
Code: _abs:
# return a < 0 ? -a : a;
cmp r8,r0,0
mi.not r1,r8,0
mi.add r1,r0,1
mi.mov r15,r0,TestAbs_5
TestAbs_4:
mov r2,r8
mov r1,r2
TestAbs_5:
mov r15,r13,0
_________________Robert Finch http://www.finitron.ca
|
| Wed Aug 02, 2017 7:44 am |

|
|
|
Revaldinho
Joined: Tue Apr 25, 2017 7:33 pm
Posts: 32
|
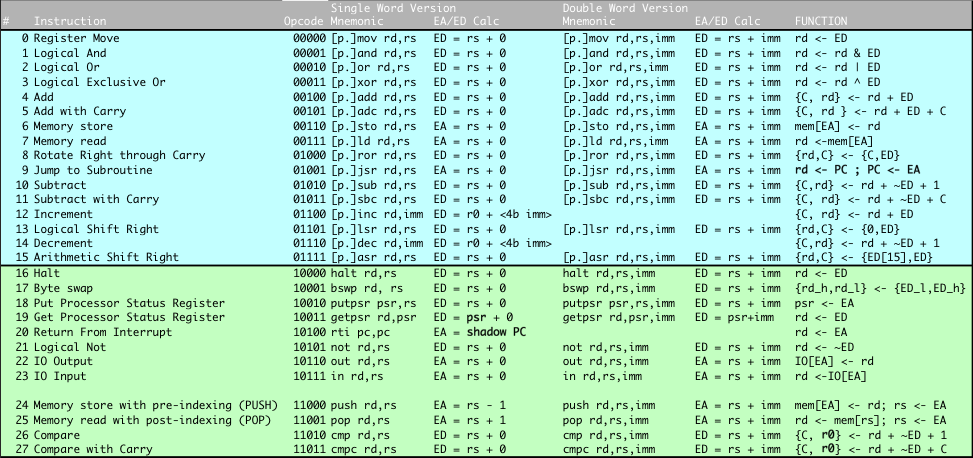
Hi Rob, I've just posted a new spec page for the OPC6 machine( https://revaldinho.github.io/opc/opc6spec.html). It's not complete but there is a useful instruction table there now. Pretty much all instructions set the flags, not just the compare. The exceptions are stores and any instruction using PC (R15) as destination, where all flags are preserved. So, I'm afraid your code won't work as it is because the predication does change after the compare. This is what you might write instead for the min function in OPC6 assembler, but I don't know how easy this is to map to your code generator. Code: # min: (a<b) ? a : b
mov r1,r8 # preload a into r1
cmp r8,r9 # compare a<b ?
pl.mov r1,r9 # revised decision if a>= b
And in fact absolute function skip the compare altogether to make good use of other instructions setting the flags Code: # abs: (a<0) ? -a: a
not r1,r8 # Preload -a into r1
inc r1,1
mi.mov r1,r8 # revised decision if -a is negative (ie original a was positive)
Looks like great progress on the compiler so far. Thanks very much for diving in. Rich
|
| Wed Aug 02, 2017 8:19 am |
|
|
|
BigEd
Joined: Wed Jan 09, 2013 6:54 pm
Posts: 1884
|
Oops, crossed in post, but let's see if we have the same take:
Interesting... I think none of those will work as expected at present. Most instructions update the zero and minus flag bits, the exceptions being
- store
- when PC is the destination
- jsr and putpsr instructions
The carry flag is only updated by adds, increments, subtracts, compares, decrements, and shifts.
So maybe it will go better if you can use the carry flag?
|
| Wed Aug 02, 2017 8:22 am |
|
|
|
robfinch
Joined: Sat Feb 02, 2013 9:40 am
Posts: 2505
Location: Canada
|
Okay, I re-worked the compiler so it outputs code more likely to run successfully. I tried to get it to re-arrange code more optimally. Here is output for abs(). It's pretty obvious that a good assembly language programmer could get two or three times the performance out of the machine in half the bytes. Note the compiler supports the asm keyword so it's possible to code in assembly language. (This is the optimized code, the code without optimization is twice the size). Code: code
_abs:
# return a < 0 ? -a : a;
cmp r8,r0,0
pl.mov r15,r0,TestAbs_4
not r1,r8,0
add r1,r0,1
mov r15,r0,TestAbs_5
TestAbs_4:
mov r1,r8
TestAbs_5:
mov r15,r13,0
_________________Robert Finch http://www.finitron.ca
|
| Wed Aug 02, 2017 1:36 pm |
|
|
|
BigEd
Joined: Wed Jan 09, 2013 6:54 pm
Posts: 1884
|
You may not be ready for this yet, but just a reminder that you can save code size and improve speed by using more single-word instructions. For example Code: _abs:
# return a < 0 ? -a : a;
cmp r8,r0,0
pl.mov r15,r0,TestAbs_4
not r1,r8,0
add r1,r0,1
mov r15,r0,TestAbs_5
TestAbs_4:
mov r1,r8
TestAbs_5:
mov r15,r13,0
could be something like Code: _abs:
# return a < 0 ? -a : a;
cmp r8,r0
pl.inc r15,TestAbs_4-PC
not r1,r8
inc r1,1
inc r15,TestAbs_5-PC
TestAbs_4:
mov r1,r8
TestAbs_5:
mov r15,r13
|
| Wed Aug 02, 2017 7:30 pm |
|
|
|
Revaldinho
Joined: Tue Apr 25, 2017 7:33 pm
Posts: 32
|
Yes, definitely best to remove explicit zero immediates because those instructions will end up being assembled into two words rather than one and take 4 cycles to execute as opposed to 2. Also, I should have spotted this earlier, but you can make the 2's complement operation cheaper by making use of the OPC's fixed effective address/data calculation. You can get a 2's complement of a register in a single instruction If you do this for example then actually what happens is Code: effective data = ( r1 - 1) & 0xFFFF
r1 <- NOT(effective data) and that's going to have the same effect as your two instruction sequence Code: not r1,r1
add r1,r0,1 .. but takes two words and 4 cycles compared with 3 words and 4 cycles (trust me - there's some overlap of fetch/execute and skipping of states given the r0 source register here). OK no cycles advantage but less code. And less code is good for cycles anyway as soon as we start using a cache. And we have started using a cache. We should add a NEG() macro for this one. Still on making (unintended) use of the effective address/data calculation you can get a kind of 3 operand instruction which can be handy sometimes, e.g. which gives you r1 =r2 + immediate rather than the r1 = r1 + (r2 + immediate) which you would get if using the conventional add r1,r2,immediate instruction. The mov instruction here doesn't affect the carry flag (because EA/ED calculations never do). Hoglet found this to be a benefit rather than a drawback when making our original PUSH/POP macros, so that the carry could be used as a parameter or return value for subroutine calls. And speaking of PUSH/POP, I should push you towards OPC6 which is substantially the same machine as OPC5-LS - very minor tweaks in source required for the PUTPSR/GETPSR mnemonics but otherwise your OPC5LS assembler source should work unchanged. OPC6 gives you some bonus instructions which can definitely improve compiler output. Amongst these are native push and pop available in both single word and dual word versions (see the instruction table). e.g. Code: push r1, r14 # predecrement r14 and then store r1 to memory[r14]
pop r1, r14 # load r1 from memory[r14] and post-increment r14
push r1, r14, -7 # pre-index r14<- r14-7, and then store r1 to memory[r14]
pop r1, r14, 7 # load r1 from memory [r14] and then post-index r14<- r14+7 The indexing operation doesn't affect the flags in common with all other effective data/address calculations - it's the load operation in these cases which sets Z and sign flags. Previously these were expensive operations to make out of individual load/store and register increment operations. Now they are native operations and Hoglet has already recoded his copro firmware to use them and got a 22% code size reduction! (We should have done this sooner!) You can use any register as a stack pointer by the way, have multiple stacks even, but conventionally we have been using r14 with subroutine call and returns. Also new in OPC6 are inc and dec - single word instructions which can increment or decrement a register using a short 4 bit unsigned immediate in place of the usual source register field. Big code and cycle savings seen here with the pi benchmarks which we posted about above. It might be more difficult for the compiler to make use of inc/dec as very short branches when used with the PC as destination, but that's a possibility too. e.g. Code: inc r1, 7 # r1 <- r1 + 7, usual flags set
dec r3,5 # r3 <- r3 - 5 , usual flags set
inc pc,7 # increment pc (synonym for r15) by 7 as a short branch (no flags set)
dec pc,6 # decrement pc by 6 for a backwards branch. In the pc cases above the starting pc value is the address of the next instruction similar to branches in other micros - ie inc pc,0 is effectively a NOP. And just a note on the assembler, it is now possible to write ... and it will know what you meant and correctly assemble that to be ...which should make it just a little easier to deploy with those PC relative branches. Also new in OPC6 are native subroutine calls. Previously you needed to load up the link register with a return address and then load the PC with the subroutine address. We used a macro for that - 4 words for a subroutine call in general. Now there's a native jsr instruction e.g. Code: jsr r13, r5, imm # jump to location r5+imm and store return address in r13
jsr r13, r0, imm # jump to absolute location imm and store return address in r13
jsr r13,r4 # speed demon code jump to location held in r4 - one word, 2 cycles Nothing magic about r13. You can use any register to hold the return address, but again conventionally we have used r13. There is no corresponding rts type return instruction - that's already covered by a simple register transfer which you're already using: Code: mov pc,r13 # load pc with link register value So that's all new stuff on OPC6. Everything, emulator, assembler and verilog core is pretty much at the self-imposed 'One Page Computer' limit of 66 lines of code so we don't have any other instructions in mind to be crammed in. Never say never, but this looks like a good cut and we're more focussed now on building systems and software (and very interested in your compiler). Just for completeness then, and you may already have spotted these in the github repo, but we are clearly missing a few shifts and rotates in the native set for which we have macros which are simple aliases Code: ASL (r1) = add r1,r1 # arithmetic shift left
ROL (r1) = adc r1,r1 # rotate left though carry I hope you find something usable in here for the compiler.
|
| Wed Aug 02, 2017 9:14 pm |
|
Who is online |
Users browsing this forum: chrome-131-bots, claudebot and 2 guests |
|
You cannot post new topics in this forum
You cannot reply to topics in this forum
You cannot edit your posts in this forum
You cannot delete your posts in this forum
You cannot post attachments in this forum
|
|
{kind=link}