Last visit was: Tue Jul 08, 2025 11:44 am
|
It is currently Tue Jul 08, 2025 11:44 am
|
OPC7 - a 32 bit machine in One Page Computing
| Author |
Message |
|
BigEd
Joined: Wed Jan 09, 2013 6:54 pm
Posts: 1835

|
. Over the last couple of weeks, revaldinho and then hoglet have surged ahead with developments in the land of One Page Computing. Starting with the CPLD-sized OPC1 and moving through to the 16-bit OPC6ls, we'd reached the point where we had a 16-bit word-addressed machine and a BCPL which could target it. (Also a C and PLASMA) BCPL was very exciting, and it's a good fit for word-oriented machines, and it comes with a number of demo programs which were useful for testing and also for performance analysis. But this showed up a couple of issues: some programs need 32 bit arithmetic, and the 64k words of memory starts to look just a little cramped. Of course, one can write 16 bit routines to perform 32 bit arithmetic, but revaldinho found this a good point to launch into a new machine development. First step is to expand all the registers from 16 to 32 bits - that's easy. Then, the instruction set. OPC6 has variable-length instructions, some of which can be predicated and others not. The result is a bit complex, especially when fitted (or nearly fitted) into a single page of code. So, the decision is made to go for fixed-length instructions, and also to simplify the code and the initial development and testing by removing the pipelining. With the wider instruction words, we can have a more regular instruction set where every instruction is predicated (3 bits), we have 5 bits of opcode, two register addresses (4 bits each) and finally a literal of 16 bits. The previous machines had an optional literal, and now we always have one. We use the same tactic, where the effective address is a wrapping addition of the source value and the (sign-extended) literal. That gives us all the addressing modes we need, without any addressing modes. (It's a load-store machine where the PC is a register and there's an always-zero register.) With 5 bits of opcode, we can bring in all the instructions from OPC6, remove the few which no longer make sense now that the literal is always present, and we have some room for some more instructions. With such a similar machine to the previous ones, we can also write a script to translate OPC6 assembly to OPC7 assembly, imperfectly and incompletely, ready for hand-finishing. So revaldinho did, and was able to port some assembly language demos. By the same token, hoglet was able to port the OPC6 monitor fairly readily to OPC7 land (although the disassembler needed some work and the single-stepper might still be a work in progress) and revaldinho expects to port the BCPL machinery and begin to extend the BCPL demo suite with some 32-bit wonders. I may have some details wrong, but that's a broad outline of the story - more to come! Including an update of our minisite. [Edit: oops, corrected the idea that BCPL is already working.]
|
| Mon Nov 06, 2017 11:40 am |
|
|
|
BigEd
Joined: Wed Jan 09, 2013 6:54 pm
Posts: 1835
|
One wrinkle in the world of 32-bit RISCy machines is how to deal with addresses, which readily fit in a register but may not fit in an instruction. And similarly how to deal with literal values up to full register size.
The OPC7 has the always-present and sign-extended 16 bit literal field, which is great for offsets and local branches and small constants, but it's not enough. And 16 bits of address range is really not doing the machine justice...
... so revaldinho reused a trick from OPC6, which is to use the 4 bit source register field as an extension to the 16 bit literal in a few chosen cases. That gives us a 20 bit (signed) reachable address space, which is in fact a useful amount of physical memory - 1M words.
For constants, a second tactic is needed - some way to load word-sized values efficiently. In this case, we went for a MOVT instruction to load the top half of the destination register from the bottom half of the effective value, leaving the bottom half of the destination alone.
To support other long-distance operations, we also have some 'long'-mode instructions:
ljsr lmov lsto lld
which have a 20 bit literal subsuming the place of the source register, which acts as if it were r0 (containing zero.)
|
| Mon Nov 06, 2017 12:33 pm |
|
|
|
BigEd
Joined: Wed Jan 09, 2013 6:54 pm
Posts: 1835
|
Just to indicate the current state of play, at time of writing:
- the instruction set seems to have stabilised (see below)
- the verilog model simulation, emulator, assembler and monitor all seem to be behaving well (monitor is not feature-complete)
- hoglet has run the OPC7 on the BlackIce FPGA board, using only on-chip RAM for now, at 25MHz and at 50MHz (with a wait state)
- OPC7 seems to come out well over 100MHz on Spartan LX9 but that's only a timing analysis result
- work is proceeding on a branch in github, with a merge likely soon
On the subject of the instruction set, we had some to-and-fro about whether we wanted ADD, ADC, or both. We ended up with ADC, in part because it offers a free ROL instruction, which is useful. And with ADC, it's easier to do multi-precision arithmetic, for applications which want more than 32 bits. (Edit: oops, no, we went the other way, with ADD! Hat tip to hoglet for the correction.)
The other discussion, most recently, was about byte-swapping, byte-rotating and byte order. We've got some preference for a little-ended machine, inasmuch as that means anything when we don't have byte addressability, but for example reading multibyte hex in srecord formats does mean we see big-endian data, in a sense. Anyway, revaldinho came up with the BPERM instruction which permutes the bytes of the source according to a lookup table in the literal, which allows for byte-swapping, half-word-swapping, byte rotation and other useful possibilities. It also turns out to be cheap, in both time and space.
|
| Mon Nov 06, 2017 4:30 pm |
|
|
|
BigEd
Joined: Wed Jan 09, 2013 6:54 pm
Posts: 1835
|
Lightning update: the merge is now in, so the master branch now has all the OPC7 goodness, and the minisite has the OPC7 spec. Here's the instruction set table from the spec - may be subject to minor changes: 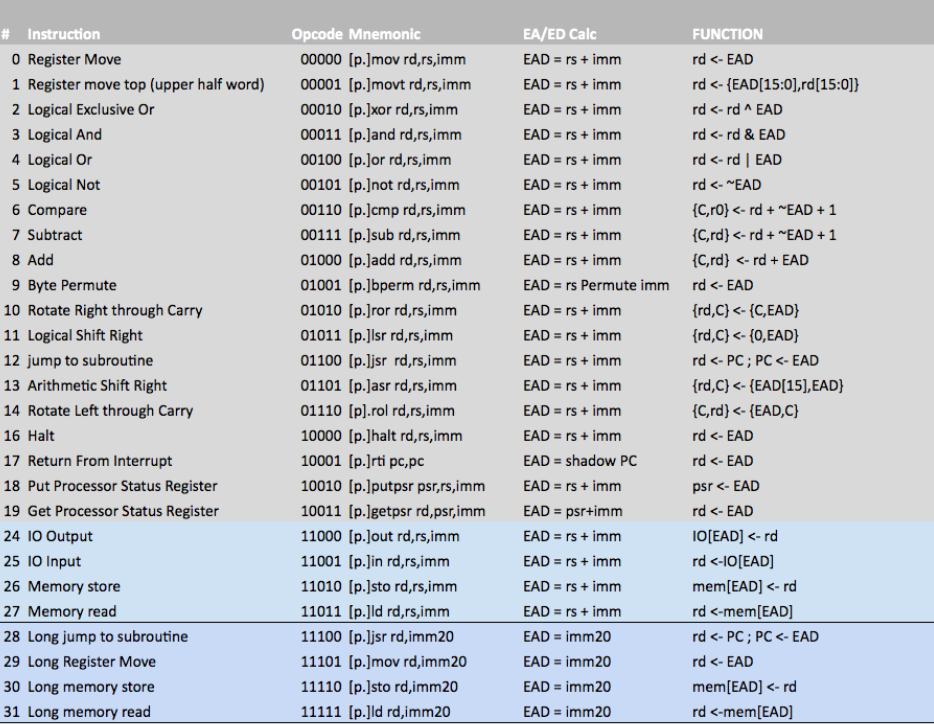
|
| Mon Nov 06, 2017 9:41 pm |
|
|
|
BigEd
Joined: Wed Jan 09, 2013 6:54 pm
Posts: 1835
|
We've made some real progress in the past week: Dave wrote a ROM so the OPC7 can act as a second processor to a 6502-based BBC Micro, which gives us keyboard, video, serial, sound, filesystem service, Rich made a great leap forward with the BCPL backend, and I was able to transmogrify Dave's existing C model of the OPC6 into an OPC7 - with a bit of help from Dave. With that C model, we can run in a Pi-based second processor connected to the Beeb's Tube interface, and with the existing HDL we can run in an FPGA-based board similarly connected. Here's a photo of the FPGA version: In porting from OPC6 to OPC7 we had to address many upgrades of things from 16 bit to 32 bit, and deal with the implicit sign-extension which OPC7 gives to short literals. We were also briefly caught out by 'pop' changing from a single instruction to a macro. If the first instruction of the macro updates the PC, then the second instruction isn't going to be executed! I think we run, on the Spartan 3 FPGA, at 50MHz, with two clock cycles per instruction. Once everything looks good and we have code to run, Rich has ideas for a more aggressive microarchitecture. The bperm instruction was again interesting. Here's the spec: - the 16 bit literal is taken as four nibbles, each acting as an index into the source - bperm r2, r1, 0x3210 is just a copy from r1 to r2 - bperm r2, r1, 0x0123 will reverse the order of the four bytes - an index of 4 means a literal zero, so - bperm r2, r1, 0x4441 will put just byte 1 into the byte 0 position, zeros elsewhere In verilog, that's Code: wire [7:0] bytes0 = {8{~OR_q[2] }} & ((OR_q[1])? ((OR_q[0]) ?RF_sout[31:24] :RF_sout[23:16]):(OR_q[0]) ? RF_sout[15:8]:RF_sout[7:0]);
wire [7:0] bytes1 = {8{~OR_q[6] }} & ((OR_q[5])? ((OR_q[4]) ?RF_sout[31:24] :RF_sout[23:16]):(OR_q[4]) ? RF_sout[15:8]:RF_sout[7:0]);
wire [7:0] bytes2 = {8{~OR_q[10]}} & ((OR_q[9])? ((OR_q[8]) ?RF_sout[31:24] :RF_sout[23:16]):(OR_q[8]) ? RF_sout[15:8]:RF_sout[7:0]);
wire [7:0] bytes3 = {8{~OR_q[14]}} & ((OR_q[13])? ((OR_q[12])?RF_sout[31:24] :RF_sout[23:16]):(OR_q[12])? RF_sout[15:8]:RF_sout[7:0]);
and my attempt to write in C looks like this: Code: case op_bperm: // pick off one of four bytes from source, four times.
res = 0;
ea_ed = s.reg[src];
res |= ((operand & 0xf) == 4) ? 0 : 0xff & (ea_ed >> (8 * (operand & 0xf) ));
operand >>= 4;
res |= ((operand & 0xf) == 4) ? 0 : (0xff & (ea_ed >> (8 * (operand & 0xf) ))) << 8;
operand >>= 4;
res |= ((operand & 0xf) == 4) ? 0 : (0xff & (ea_ed >> (8 * (operand & 0xf) ))) << 16;
operand >>= 4;
res |= ((operand & 0xf) == 4) ? 0 : (0xff & (ea_ed >> (8 * (operand & 0xf) ))) << 24;
s.reg[dst] = res;
break;
(There's probably a better way.) But the main point is that in hardware it's quite simple: just a bunch of muxes and some minimal decode and some AND gates. And as this permutation happens in the effective address calculation, it doesn't hit the critical path - it runs in parallel with the usual function which is an addition.
You do not have the required permissions to view the files attached to this post.
|
| Tue Nov 21, 2017 5:08 pm |
|
|
|
monsonite
Joined: Mon Aug 14, 2017 8:23 am
Posts: 157
|
Ed,
Thanks for the update on OPC7 - and very pleased to hear that Dave took the time to try it out on the BlackIce board - albeit using the ICE40's internal BRAMS for 32bit wide storage.
Interesting to hear that there is now the possibility with the OPC7 of a general purpose 100MHz cpu that can now be implemented in a Spartan 3 FPGA - and work as a co-pro to the venerable BBC micro.
I was specifically interested in the byte permutation method - as this hints at a way how the contents of a small number of registers could be accessed and manipulated within a stack based machine.
regards
Ken
|
| Tue Nov 21, 2017 6:50 pm |
|
|
|
BigEd
Joined: Wed Jan 09, 2013 6:54 pm
Posts: 1835
|
I should add, the photo was taken at the weekend's Acorn-centric ABUG meetup near Leicester, and one of the first things I managed to do was talk to the OPC7 running on the BlackIce board: Code: MacBook-Air:opc7 ed$ screen /dev/cu.wchusbserial1410 115200
OPC7 Monitor
-200gOk 3.14159 I neglected to take a photo of that setup. Soon after that the focus shifted to get the second-processor version running. We did have some trouble, which Dave has very recently fixed, caused by our decimal print routine being a bit too 16-bit, so Dave has replaced it with a more general word-sized decimal print routine. We don't (yet) have a single-step trace in the monitor code, so emulation is the best way to dig into the detailed (mis)behaviour of the machine - or the code. At the same event, Rich did much of the finishing off of the BCPL backend for the OPC7. Today, we have a fair number of BCPL test programs and a working core and ROM to run them on. I should run some and take some photos. There might yet be space in the BlackIce to fit both the BBC host and a second processor, and that would be a nice, affordable, self-contained environment to play with the new CPU, in a world with well supported input and output and a filing system. Running test cases from an SD card beats having to paste them in as srecords, and there's no need to write a filing system for the new CPU, only the small ROM to interface with the host. Both the BlackIce and the GOP platforms have narrow SRAM compared to the 32-bit machine width, but as Dave was previously able to interface the 16-bit OPC6 with the 8-bit wide RAM on the GOP, I would imagine the same kind of tactics would handle the width mismatch on both platforms for the OPC7. There's a performance penalty of course, mitigated to some effect by implementing a small instruction cache. It will be good to see something like bperm popping up in a stack-based machine!
|
| Tue Nov 21, 2017 7:52 pm |
|
|
|
BigEd
Joined: Wed Jan 09, 2013 6:54 pm
Posts: 1835
|
One facility that's very powerful, which helped Dave identify a bug in the 'cmp' instruction, is the debugger which is optionally built into the C model running on the Pi. You can then talk to the debugger over the Pi's serial port to investigate what's going on, with breakpoints and watchpoints and so on: Quote: I think there is a bug in CMP: R1 = 0x7F cmp r1, r0, 00000080 leaves C=1 and it should leave C=0 I'll pause now, in case I'm spoiling your fun!!! Dave Code: >> break 466
Exec breakpoint set at 466
>> c
Running
>> cycle counter = 94438996864
I_CACHE_MISS = 63749853
D_CACHE_MISS = 137550
tube reset - copro 7
Exec breakpoint hit at 466
00466 06100080 : cmp r1, r0, 00000080
>> r
R0 = 0000
R1 = 007f
R2 = 0476
R3 = f00320
R4 = 0000
R5 = 0000
R6 = 0000
R7 = 0000
R8 = 0000
R9 = 0000
R10 = 0000
R11 = 0000
R12 = 0040
R13 = 0465
R14 = 0ffd
PC = 0466
PSR = SWI:0 EI:1 S:0 C:0 Z:0
PC_int = 0000
PSR_int = 0000
>> s
Stepping 1 instructions
00467 80f00470 : c.mov r15, r0, 00000470
>> r
R0 = ffffffff
R1 = 007f
R2 = 0476
R3 = f00320
R4 = 0000
R5 = 0000
R6 = 0000
R7 = 0000
R8 = 0000
R9 = 0000
R10 = 0000
R11 = 0000
R12 = 0040
R13 = 0465
R14 = 0ffd
PC = 0467
PSR = SWI:0 EI:1 S:1 C:1 Z:0
PC_int = 0000
PSR_int = 0000
>> As it happens, my setup at the time wasn't recognising my serial adapter so I couldn't follow suit - I was in Leicestershire and Dave was debugging in Bristol.
|
| Tue Nov 21, 2017 7:57 pm |
|
|
|
hoglet
Joined: Tue Feb 10, 2015 7:07 am
Posts: 52
|
BigEd wrote: Both the BlackIce and the GOP platforms have narrow SRAM compared to the 32-bit machine width, but as Dave was previously able to interface the 16-bit OPC6 with the 8-bit wide RAM on the GOP, I would imagine the same kind of tactics would handle the width mismatch on both platforms for the OPC7. There's a performance penalty of course, mitigated to some effect by implementing a small instruction cache.
I did update the external memory controller used in the GOP to allow the RAM data width to be a parameter: https://github.com/revaldinho/opc/blob/ ... ntroller.v(The comments still refer to the fixed 16-bit wide version) We've never tried to use this with BlackIce - I would anticipate issues, because the cache ends up being built with large numbers of discrete registers. But even without the cache it would be useful. Dave
|
| Wed Nov 22, 2017 8:17 am |
|
|
|
BigEd
Joined: Wed Jan 09, 2013 6:54 pm
Posts: 1835
|
Good point Dave (Lattice FPGAs don't offer the LUT-efficient distributed RAM which Xilinx FPGAs do, and which is great for register files and small caches. So on Lattice these things take up more LUTs and more routing.)
I've slightly changed my mind about the preference for bringing up a new CPU as an Acorn copro - it works very well for those of us who've already internalised enough Acorn knowledge, but having a serial connection to a sufficiently useful monitor program might be preferable to someone who hasn't. If the monitor program can load code then it can be improved in-place: in our case we use srecord format.
In fact, Rich (revaldinho) pointed out that a test framework on a laptop could automatically squirt test code to the CPU and harvest the responses, so one could regression test an update at full speed, instead of waiting for emulation or simulation. For example, python can readily pick files from directories and send encoded data out of a serial port.
|
| Wed Nov 22, 2017 8:24 am |
|
|
|
hoglet
Joined: Tue Feb 10, 2015 7:07 am
Posts: 52
|
So we have a number of possible things to work on at our next Bristol mini-meet:
- re-writing the OPC6 single step code to work with OPC7
- enhancing the OPC Tube Client ROM to add some of the missing MOS API
- adding an external memory controller to the BlackIce build
On the last item, I note that even when targeting Xilinx Spartan 3 or 6, the memory controller cache uses discrete registers rather than distributed RAM. I don't really understand why this is, so it probably merits further investigation. The cache is one-way-direct-mapped, and there is a single tag comparator.
Dave
|
| Wed Nov 22, 2017 8:33 am |
|
|
|
robfinch
Joined: Sat Feb 02, 2013 9:40 am
Posts: 2382
Location: Canada
|
The bperm instruction reminds me of the BMM (bit matrix multiply) instruction which can also do permutations found in some machines. BMM probably requires more logic resources though.
_________________Robert Finch http://www.finitron.ca
|
| Wed Nov 22, 2017 1:19 pm |

|
Who is online |
Users browsing this forum: claudebot and 0 guests |
|
You cannot post new topics in this forum
You cannot reply to topics in this forum
You cannot edit your posts in this forum
You cannot delete your posts in this forum
You cannot post attachments in this forum
|
|