I’m toying with the idea of a superscalar 6502. It would work by changing 6502 opcodes into micro-ops in a manner similar to what’s done for the x86. So, I need to have worked out an appropriate set of micro-ops. The micro-ops would be a load / store architecture with a fixed 13-bit instruction format. I think all instructions can be implemented with a maximum of four micro-ops. This means a table of 54 bits for each instruction (2 bits used to indicate # of micro-ops). The table would be indexed by the opcode byte and a field (Ld3) in the micro-op instruction indicates when to take values from the macro-op instruction. Necessary for constants supplied by macro-ops.
Micro-op table follows:
Attachment:
File comment: 6502 Micro-op table
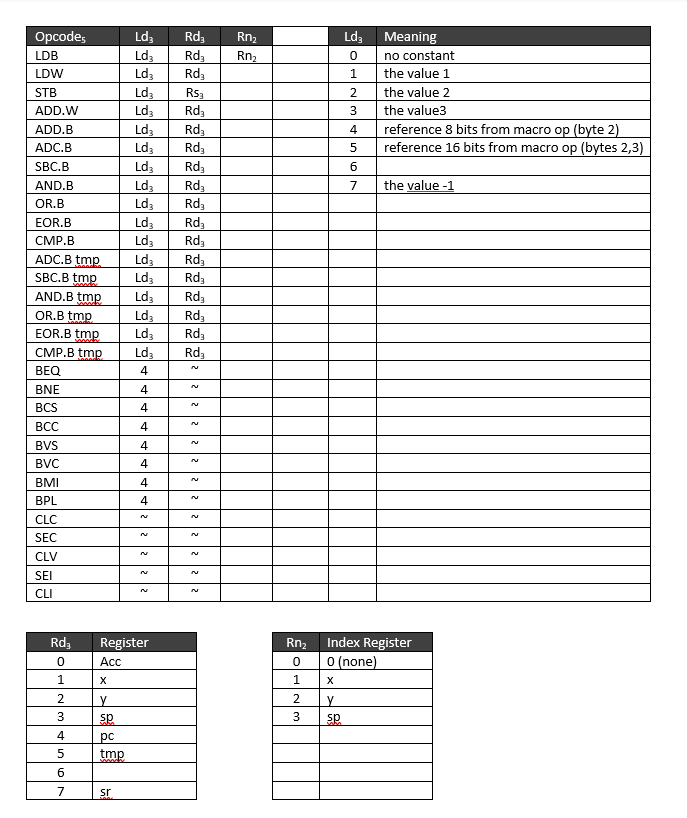
microops.png [ 36.17 KiB | Viewed 7252 times ]
microops.png [ 36.17 KiB | Viewed 7252 times ]
Some sample instruction breakdowns:
Code:
[b]pha[/b]
SB acc,sp
ADD.B sp,#-1
[b]adc (zp),y[/b]
LDW tmp,zp
ADD tmp,y
LDB tmp,[tmp]
ADC.B Acc,tmp
[b]rti[/b]
ADD.B sp,#1
LDB sr,sp
ADD.B sp #2
LDW pc,sp-1
[b]rts[/b]
ADD.B sp,#2
LDW pc,sp-1
ADD.w pc,#1
SB acc,sp
ADD.B sp,#-1
[b]adc (zp),y[/b]
LDW tmp,zp
ADD tmp,y
LDB tmp,[tmp]
ADC.B Acc,tmp
[b]rti[/b]
ADD.B sp,#1
LDB sr,sp
ADD.B sp #2
LDW pc,sp-1
[b]rts[/b]
ADD.B sp,#2
LDW pc,sp-1
ADD.w pc,#1