Last visit was: Sat Jul 18, 2026 7:04 am
|
It is currently Sat Jul 18, 2026 7:04 am
|
Deferred calculation of processor flags
| Author |
Message |
|
spiff
Joined: Mon Dec 28, 2015 11:37 am
Posts: 13

|
In old 8-bit processors the status register flags are automatically updated on executing an instruction.
-Some status register flags are processor state that determining what state the processor is in. I - Interrupt enable, D - Decimal mode.
-Some are used in calculations, C – Carry, H – Half-carry, and store parts of the result from the operation.
-Some flags are updated from the result of the last operation, Z – Zero, N – Negative, P - Parity, , V - Overflow.
The last group of flags are never used within an instruction to calculate the new result. They are only used in Branch instructions to determine if a branch should be taken or not. What if we remove the automatic calculation of these flags from the execution path, and only calculate them when needed in a branch instruction? This should shorten the execution time of operations in the ALU and might make the processor able to run a little bit faster clock speed.
The V - Overflow flag use multiple operands of the operation, and might be easier to calculate during the execution of the operation.
When executing a branch on any of the Z, N, P flags, on the second cycle when the processor fetches the branch target offset, it will have a free cycle to calculate the value of the flag used in the branch from the previous operation result. The value is then ready in the third cycle to determine if the branch should be taken or not. Thus, the deferred calculation of the flag does not incur any penalty cycles compared to if it were previously calculated.
This will also mean that these flags are no longer needed in the status register, and will free the bits for other uses.
Removing them will not break interrupts and return from interrupts as the accumulator will still holding the latest result.
The above reasoning is of course flawed. The last result is not always stored in the accumulator as some operations are done directly on memory and then the flags cannot be recalculated without having the result present. Some operations do not even store a result at all but only update the flags.
However, the result from such operations may still be available inside the processor in a data buffer and maybe can be reused to calculate the flags. But to make this work with an interrupt system that buffer must also be stacked.
The last paragraph might actually make the V – Overflow bit superfluous also, and better calculated on test only.
The all above is an insights that struck me when looking into a Test instruction. The objective of all might be to remove unnecessary bits from the status register or maybe shorten the execution path of the ALU. While this is only an outdated theoretical topic, maybe with some further ideas the limitations can be worked around or be used with other restrictions.
|
| Wed Nov 23, 2022 4:35 pm |
|
|
|
BigEd
Joined: Wed Jan 09, 2013 6:54 pm
Posts: 1885
|
It's certainly a tactic sometimes used by emulators, to calculate the more expensive flags only when needed.
|
| Wed Nov 23, 2022 5:55 pm |
|
|
|
Ken KD5ZXG
Joined: Sat Sep 03, 2022 3:04 am
Posts: 51
|
I lookup result and flag separately. Sometimes we only need the result bytes and no need to examine what flag bits might have done. Sometimes we only need flags and ignore the result. No reason to gather information that won't be used. Also because flags are a wasteful fit to memory for simultaneous access.
|
| Fri Feb 24, 2023 9:26 pm |
|
|
|
oldben
Joined: Mon Oct 07, 2019 2:41 am
Posts: 939
|
Flags are a tricky topic. I just use the carry flag as status. Since I don't have a 'CMP' instruction have no need for flags.
BCC tests a AC for + - Zero. SCC sets a AC 0/1 for condition. This works for this CPU. Add,sub set the carrry flag,
Adx,sbx has no effect. Ben.
|
| Sat Feb 25, 2023 8:42 am |
|
|
|
mmruzek
Joined: Sun Dec 19, 2021 1:36 pm
Posts: 121
Location: Michigan USA
|
Hi, I believe you are describing Predication, which very loosely is making a instruction (usually a branch) conditional on the state of a flag that is created concurrently during the instruction's execution. https://en.wikipedia.org/wiki/Predicati ... chitecture) I posed a similar question to your question on the Vintage Computer Forum and received this very insightful set of replies: https://forum.vcfed.org/index.php?threa ... l.1239938/What most surprised me was the statement that this technique was used in the Apollo Guidance Computer, among others. My project the LALU computer is capable of predication and I use it for all my conditional branches. I don't use predication for any other instructions at the moment, but I think it could be put to good use for memory operations. Michael
|
| Sat Feb 25, 2023 12:14 pm |

|
|
|
Ken KD5ZXG
Joined: Sat Sep 03, 2022 3:04 am
Posts: 51
|
74181 had an infamously slow open collector AND4 gate. Supposedly to test for A=B, but instead watching for 1111, inverse zero.
Aside from poorly described function, that gate presents a long needless wait after every result for a flag that often won't be used.
Even with faster external AND gates, busywork more often ignored than referenced.
I've taken shine to a series prefixed Manchester Magnitude Comparator chain that can test any combo of < = > on demand.
Two of those eight possible combos accelerate arithmetic by revealing all Borrows without ripple was the main purpose.
Can't directly test Zero, but can test A=B , A<>B by wasting a cycle. Tests of Carry or Borrow are free with arithmetic.
If an extra cycle might check A=0 only before certain branches, is a real Zero test at the end worth the repeated delay?
Last edited by Ken KD5ZXG on Thu Apr 20, 2023 1:17 pm, edited 1 time in total.
|
| Wed Apr 19, 2023 9:44 pm |
|
|
|
oldben
Joined: Mon Oct 07, 2019 2:41 am
Posts: 939
|
I always thought the 74181 was ment for active low logic. Active high input data would be selected by AOI gates. Tristate logic was not invented yet in 1970 There the zero made sense. Active low output would be buffered and inverted.
Conditional logic is used for general program flow, or I/O handling.
I/O could use special tests for faster service,like a case style statement for I/O flags.
Why have a fast branch in a I/O busy loop, when a I/O wait instruction or I/O sleep instruction might work better.
Ben.
|
| Thu Apr 20, 2023 3:52 am |
|
|
|
Ken KD5ZXG
Joined: Sat Sep 03, 2022 3:04 am
Posts: 51
|
Perhaps a snooze mode that slows but doesn't quite stop the clock till something of interest happens?
You may have memory to refresh or keyboard matrix to scan. Stoppage till interrupt might complicate.
------------- on a different note ------------
Fine to toss an alternate speculative result. Discarded effort that speeds operation is not entirely wasted.
I dislike wasteful computation of every possible function, to discard multiple efforts for no real benefit.
The same might be said for flags, yet I lookup a word packed with many flags and MUX away all but one.
Not quite the same thing, since those calculations were done in advance, only once and never repeated.
|
| Thu Apr 20, 2023 1:18 pm |
|
|
|
cjs
Joined: Thu Dec 05, 2019 7:53 am
Posts: 18
Location: Tokyo, Japan
|
spiff wrote: When executing a branch on any of the Z, N, P flags, on the second cycle when the processor fetches the branch target offset, it will have a free cycle to calculate the value of the flag used in the branch from the previous operation result. My understanding is that on processors such as the 6800 and 6502 (and probably many others) it generally doesn't take any extra cycles to calculate the flag values because they can all be calculated through combinational logic using simple equations. Consider, for example, the 6800's ADC instruction: I chose this example because the 6800 manual gives you the equations for calculating the condition codes. You'll note that these can all be implemented in combinational logic and thus calculated in parallel as you move the result from the ALU into the target register. You have the original accumulator value X, the value from memory M, and the ALU result R all there. And that it's doing this in parallel is clear from the execution times. An immediate add takes two cycles, one to load the opcode, one to load the operand as it's decoding the opcode, and then the next cycle is loading the next opcode as it completes the addition. The direct page mode is three cycles since it needs to load the opcode, load the operand, and then load the value from the direct page address given by the operand. And so on.
You do not have the required permissions to view the files attached to this post.
_________________Curt J. Sampson - github.com/0cjs
|
| Sat May 06, 2023 5:53 pm |
|
|
|
BigEd
Joined: Wed Jan 09, 2013 6:54 pm
Posts: 1885
|
There is some overlapping, at least on the 6502, although I wouldn't quite call it deferring. If you look at the tabulated state changes in this simulation you'll see that the Z flag is updated in cycle 9, which is indeed the second cycle of the branch which follows the decrement. This is the program: Code: LDX #$02
DEX
BEQ skip
DEX
BEQ zero
LDA #$7f
skip:
LDA #$44
zero:
LDA #$67
NOP
NOP
|
| Sat May 06, 2023 8:13 pm |
|
|
|
robfinch
Joined: Sat Feb 02, 2013 9:40 am
Posts: 2505
Location: Canada
|
Although simple, the flags calculations require the result of the operation. So, it is faster timing wise to use another cycle to compute the flags from a registered result. Usually there is another cycle available to use to calculate flags. For example, the instruction fetch for the next instruction. Flags typically get updated a cycle after results. It could be done in one long cycle but then the CPU would be running at 1 MHz instead of 2 MHz.
_________________Robert Finch http://www.finitron.ca
|
| Sun May 07, 2023 6:44 am |
|
|
|
cjs
Joined: Thu Dec 05, 2019 7:53 am
Posts: 18
Location: Tokyo, Japan
|
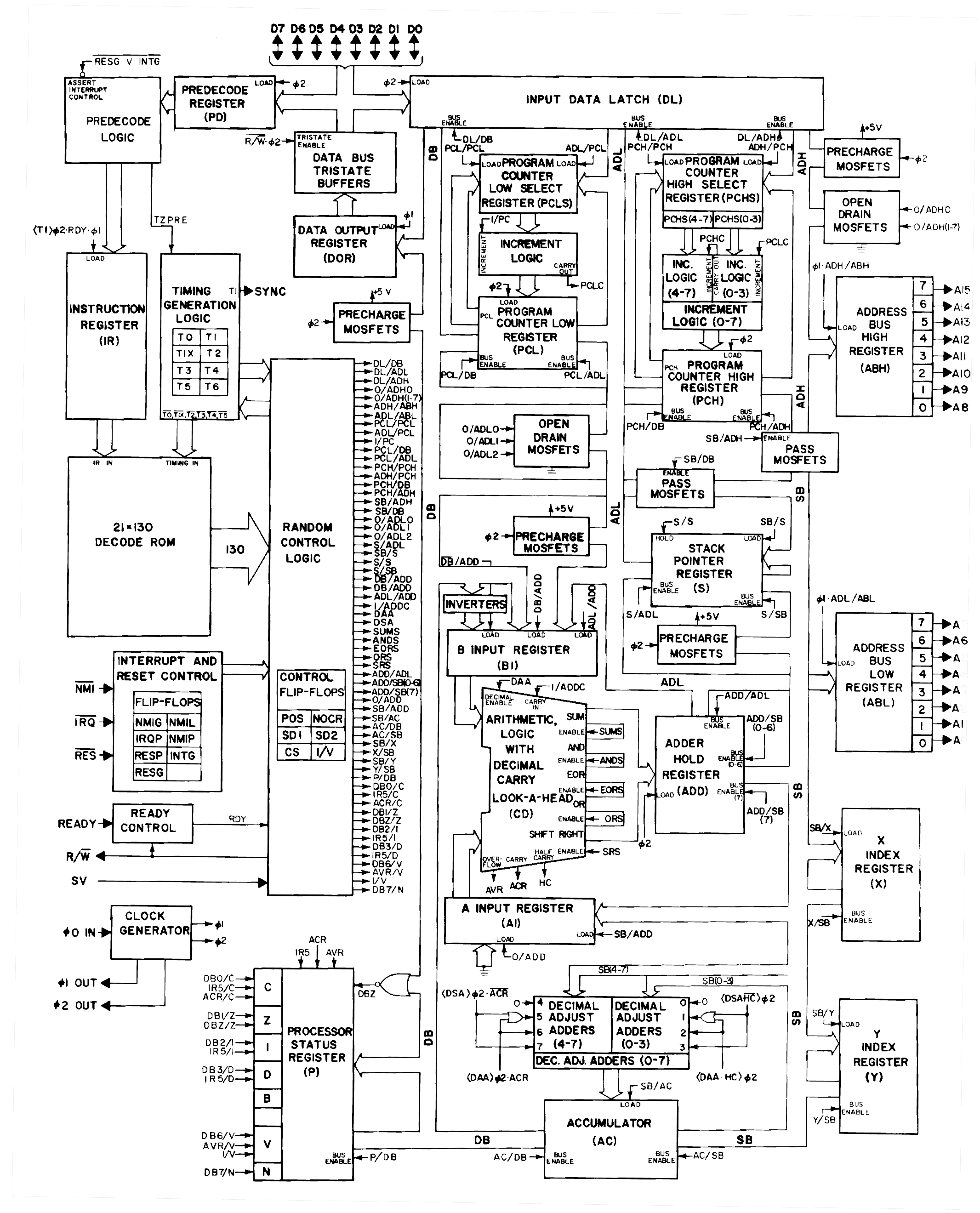
robfinch wrote: Although simple, the flags calculations require the result of the operation. So, it is faster timing wise to use another cycle to compute the flags from a registered result. Unless, of course, you also have to do something else with the result of the operation after the ALU gets done. Some of the flag calculations, as you can see from my post above, actually require not just the result but also the inputs. For example, the overflow flag is V = X₇⋅M₇+M₇⋅R̅₇+R̅₇⋅X₇⋅, where X is the input value from the accumulator, M is the input value from memory, and R is the result output from the ALU. The (almost?) inevitable conclusion is that you'll need registers within the CPU, not visible to the programmer, to hold at least two of these. Probably you want temporary registers for all three, separate from the accumulator, because otherwise you have to use different source registers for flag calculations depending on whether you're doing SUB (X and M in temps, result in accumulator) or CMP (X in accumulator, M and result in temps). And looking at the classic 6502 architecture diagram, we do indeed see three hidden registers for this purpose right around the ALU: the A input register (AI), the B input register (BI) and the adder hold register (ADD), all separate from the accumulator (AC): Attachment: 6502-ALU-registers.jpg This means that there needs to be another step after the ALU has completed an ADC instruction and placed the result in ADD: copying that result to AC. (And, on the 6502, doing a decimal adjust on the result at the same time if you're in decimal mode.) You can calculate the flags from AI, BI and ADD in parallel with copying ADD to AC. So there's no "extra cycle" for the flags; if the flag calculations were not done you'd still have to have a cycle to put the result in AC anyway.
You do not have the required permissions to view the files attached to this post.
_________________Curt J. Sampson - github.com/0cjs
|
| Sun May 07, 2023 10:06 am |
|
|
|
BigEd
Joined: Wed Jan 09, 2013 6:54 pm
Posts: 1885
|
Modified simulation shows NVZC all updated in the same cycle as the result is written back to A: http://visual6502.org/JSSim/expert.html ... 44a967eaea
|
| Sun May 07, 2023 6:49 pm |
|
|
|
Ken KD5ZXG
Joined: Sat Sep 03, 2022 3:04 am
Posts: 51
|
robfinch wrote: Although simple, the flags calculations require the result of the operation. Score one for tables, pre-computed rather than deferred. Result lookups are optional. Flag lookup (also optional) doesn't need to wait. Not sure it saves work, but program count also reveals branch history. Are stored flags followed by deferred branches essential? We know what happened by fact of arrival or fall through. If A>B goto 1234.
|
| Wed May 10, 2023 6:56 pm |
|
Who is online |
Users browsing this forum: chrome-7x-bots, claudebot, Majestic-12 [Bot] and 0 guests |
|
You cannot post new topics in this forum
You cannot reply to topics in this forum
You cannot edit your posts in this forum
You cannot delete your posts in this forum
You cannot post attachments in this forum
|
|

{kind=link}